Browser Agent Leaderboards, rebuilt
Browser Agent Leaderboards, rebuilt
Browser Agent Leaderboards, rebuilt
/
/
San Francisco
San Francisco
/
/

Hussien Hussien
Hussien Hussien

Benchmarks rot.
A paper reports a score once and freezes. The new results show up on Twitter, in model cards, in someone's blog post, and the original source never gets updated to match. Six months later the number you're citing is neither the latest nor the highest, and you'd never know.
It's worse under the surface. Methodology drifts: a model gets deprecated, a website in the task set goes offline, the scoring harness changes, and the "same" benchmark is quietly measuring something else. No two benchmarks measure the same thing, so you can't line one score up against another. And every model release reports on a different set of benchmarks, so even the model cards are hard to compare.
Instead of chasing that across a dozen sources that each went stale on a different day, we keep one current. We rebuilt the Steel leaderboards to track results as they actually land, with the source and methodology on the page, across the benchmarks that matter for browser and computer-use agents.
Live now at leaderboard.steel.dev.
Why we maintain it
We've kept this leaderboard running since February 2025 and reshaped it three times since. This is v4, and we're honestly still hunting for the right form.
We maintain it for a selfish reason. Every Steel project starts with the same question: which benchmark do we even trust here? Our customers ask us the other half: which agent is actually best, and how do we build on it? This is our running answer to both, in the open.
Everything on one page
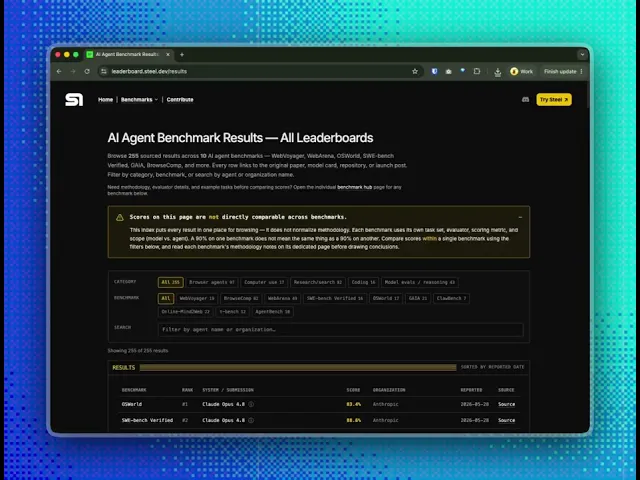
Ten benchmarks, on the homepage instead of buried a click deep: WebVoyager, BrowseComp, WebArena, SWE-bench Verified, OSWorld, GAIA, ClawBench, Online-Mind2Web, τ-bench, and AgentBench. You see the whole field the moment you land.
(The green pixel-cursor mark from the site's first release is back next to the title. Small thing. We missed it.)
We keep it current
This is the part that rots everywhere else. When a new result lands, we add it, with its date. Claude Opus 4.8 went to #1 on OSWorld at 83.4%, and it was on the board the day it shipped. The original OSWorld paper still reports what it reported at publication.
Every result also carries where it came from: source, repo, who reported it. Self-reported or third-party verified.
Scores don't compare across benchmarks
We put this at the top of the results page, not in a footnote: a 92% on one benchmark and an 80% on another is not a ranking. It's two different exams, with different tasks, scoring, and scope. Even inside a single benchmark, rows vary by evaluator, harness, attempt budget, tool access, or verification level.
Results is the one place to see it all: filter by category or benchmark, search by agent or company, freshest first.
The small stuff
Copy any results table as markdown in one click.
A table of contents that follows you down long pages.
Sharper share cards when you drop a link in Slack or X.
Come add to it
The board stays current because it's maintained, not because it's finished. If you've got a verifiable score we're missing, the contribution guide spells out exactly what evidence to bring, and there's a separate bar for proposing a whole new leaderboard.
Go look
Live now at leaderboard.steel.dev. Open a benchmark that matters to your work and read past the top row.
See the benchmark: leaderboard.steel.dev
Build the agent you want on the board: get a free Steel API key
Spot a result we missed: Discord or @steeldotdev
FAQ
What is the Steel browser agent leaderboard?
A public set of leaderboards at leaderboard.steel.dev tracking how AI agents and models perform across 10 benchmarks spanning browser agents, computer use, research, and coding: WebVoyager, BrowseComp, WebArena, SWE-bench Verified, OSWorld, GAIA, ClawBench, Online-Mind2Web, τ-bench, and AgentBench. Each result carries its source, repo, and reporter, and each benchmark page explains the task set and scoring.
How often is the leaderboard updated?
Continuously. When a new result lands, we add it with its date, rather than waiting for an original paper to revise, which it usually never does. Claude Opus 4.8, for example, was on the OSWorld board at #1 (83.4%) the day it shipped. Each row also notes when methodology drifts, like a deprecated model or a changed scoring harness, so an aging number doesn't masquerade as a current one.
Why aren't scores comparable across different benchmarks?
Each benchmark is a different exam. WebVoyager scores task completion across 643 web tasks evaluated by GPT-4V. OSWorld scores desktop automation across 369 tasks via execution-based validators in a VM. BrowseComp scores short-answer research questions. Different tasks, scoring, and scope, so a percentage on one says nothing about a percentage on another.
Which AI agent ranks #1 on OSWorld?
As of 2026-05-28, Claude Opus 4.8 leads OSWorld with 83.4%, above the 72.36% human baseline from the original paper. OSWorld measures multimodal desktop automation across 369 tasks using execution-based validators that check the final computer state after the agent acts.
How do I get my agent's score on the leaderboard?
Open a submission following the contribution guide on GitHub. It defines the evidence a score needs (source, reproducibility, and verification level) and the separate bar for a whole new leaderboard. Scores get listed on evidence, not announcements.
Should I pick an agent based on its leaderboard rank?
Treat the rank as a directional signal, not a verdict. The board shows methodology, provenance, and verification for each score, but it can't tell you about latency, cost per task, anti-bot resilience, or how an agent generalizes to your specific sites. Use it to shortlist, then test candidates on the workflows you actually run.
Benchmarks rot.
A paper reports a score once and freezes. The new results show up on Twitter, in model cards, in someone's blog post, and the original source never gets updated to match. Six months later the number you're citing is neither the latest nor the highest, and you'd never know.
It's worse under the surface. Methodology drifts: a model gets deprecated, a website in the task set goes offline, the scoring harness changes, and the "same" benchmark is quietly measuring something else. No two benchmarks measure the same thing, so you can't line one score up against another. And every model release reports on a different set of benchmarks, so even the model cards are hard to compare.
Instead of chasing that across a dozen sources that each went stale on a different day, we keep one current. We rebuilt the Steel leaderboards to track results as they actually land, with the source and methodology on the page, across the benchmarks that matter for browser and computer-use agents.
Live now at leaderboard.steel.dev.
Why we maintain it
We've kept this leaderboard running since February 2025 and reshaped it three times since. This is v4, and we're honestly still hunting for the right form.
We maintain it for a selfish reason. Every Steel project starts with the same question: which benchmark do we even trust here? Our customers ask us the other half: which agent is actually best, and how do we build on it? This is our running answer to both, in the open.
Everything on one page
Ten benchmarks, on the homepage instead of buried a click deep: WebVoyager, BrowseComp, WebArena, SWE-bench Verified, OSWorld, GAIA, ClawBench, Online-Mind2Web, τ-bench, and AgentBench. You see the whole field the moment you land.
(The green pixel-cursor mark from the site's first release is back next to the title. Small thing. We missed it.)
We keep it current
This is the part that rots everywhere else. When a new result lands, we add it, with its date. Claude Opus 4.8 went to #1 on OSWorld at 83.4%, and it was on the board the day it shipped. The original OSWorld paper still reports what it reported at publication.
Every result also carries where it came from: source, repo, who reported it. Self-reported or third-party verified.
Scores don't compare across benchmarks
We put this at the top of the results page, not in a footnote: a 92% on one benchmark and an 80% on another is not a ranking. It's two different exams, with different tasks, scoring, and scope. Even inside a single benchmark, rows vary by evaluator, harness, attempt budget, tool access, or verification level.
Results is the one place to see it all: filter by category or benchmark, search by agent or company, freshest first.
The small stuff
Copy any results table as markdown in one click.
A table of contents that follows you down long pages.
Sharper share cards when you drop a link in Slack or X.
Come add to it
The board stays current because it's maintained, not because it's finished. If you've got a verifiable score we're missing, the contribution guide spells out exactly what evidence to bring, and there's a separate bar for proposing a whole new leaderboard.
Go look
Live now at leaderboard.steel.dev. Open a benchmark that matters to your work and read past the top row.
See the benchmark: leaderboard.steel.dev
Build the agent you want on the board: get a free Steel API key
Spot a result we missed: Discord or @steeldotdev
FAQ
What is the Steel browser agent leaderboard?
A public set of leaderboards at leaderboard.steel.dev tracking how AI agents and models perform across 10 benchmarks spanning browser agents, computer use, research, and coding: WebVoyager, BrowseComp, WebArena, SWE-bench Verified, OSWorld, GAIA, ClawBench, Online-Mind2Web, τ-bench, and AgentBench. Each result carries its source, repo, and reporter, and each benchmark page explains the task set and scoring.
How often is the leaderboard updated?
Continuously. When a new result lands, we add it with its date, rather than waiting for an original paper to revise, which it usually never does. Claude Opus 4.8, for example, was on the OSWorld board at #1 (83.4%) the day it shipped. Each row also notes when methodology drifts, like a deprecated model or a changed scoring harness, so an aging number doesn't masquerade as a current one.
Why aren't scores comparable across different benchmarks?
Each benchmark is a different exam. WebVoyager scores task completion across 643 web tasks evaluated by GPT-4V. OSWorld scores desktop automation across 369 tasks via execution-based validators in a VM. BrowseComp scores short-answer research questions. Different tasks, scoring, and scope, so a percentage on one says nothing about a percentage on another.
Which AI agent ranks #1 on OSWorld?
As of 2026-05-28, Claude Opus 4.8 leads OSWorld with 83.4%, above the 72.36% human baseline from the original paper. OSWorld measures multimodal desktop automation across 369 tasks using execution-based validators that check the final computer state after the agent acts.
How do I get my agent's score on the leaderboard?
Open a submission following the contribution guide on GitHub. It defines the evidence a score needs (source, reproducibility, and verification level) and the separate bar for a whole new leaderboard. Scores get listed on evidence, not announcements.
Should I pick an agent based on its leaderboard rank?
Treat the rank as a directional signal, not a verdict. The board shows methodology, provenance, and verification for each score, but it can't tell you about latency, cost per task, anti-bot resilience, or how an agent generalizes to your specific sites. Use it to shortlist, then test candidates on the workflows you actually run.


All Systems Operational