

I had Claude Code pry its own deep-research workflow out of its binary, then pointed that workflow at a question about itself. The verdict: it searches wide and never doubles back. The systems it resembles do. The whole game is that second hop.
Claude Code ships as a single compiled binary with its brain welded shut. Somewhere inside is the workflow it runs when you ask it to research the web: scope the question, fan out searches, read, vote, write.
It does not ship as a readable file, so, for research purposes, I had Claude Code reconstruct the workflow from inside its own binary. A few minutes later the tool had performed surgery on itself and handed me the deep-research.js.
I had a theory: these "deep research" agents are not deep, they are wide. They take your question, spray it across a handful of parallel searches, pile up the results, and stamp the word deep on the box. So I pointed the exact workflow at one question, how do deep-research harnesses actually work, are they wide or deep, and let it research its own autopsy.
What I watched it do confirmed the theory and broke it in the same run.
What I was actually holding
This is a Dynamic workflow, the kind Claude Code runs when you ask it to research the web. It executes on your own machine every time you run /deep-research. Everything in this piece describes the workflow as it ships in Claude Code v2.1.170; later builds may change it.
The header comment says it was "ported from a bughunter architecture," swapping git and grep for WebSearch and WebFetch. Someone built a bug-hunting agent, then noticed the same skeleton finds facts about the world as easily as it finds null-pointer dereferences.
Reference code is how patterns spread. People read it to learn the shape, then they ship the shape. So what matters is less what it does than what it teaches everyone who copies it.
How the deep-research workflow works
Five phases. Top to bottom. Once.

Phase | What it does |
|---|---|
Scope | One agent splits the question into 5 angles: broad, technical, recent, contrarian, practitioner. |
Search | Five agents run in parallel, one per angle, each blind to the others. |
Fetch + extract | Dedup URLs, cap at 15 sources. Each source yields 2-5 falsifiable claims, each with a direct quote and a source-quality grade. |
Verify | Three skeptics per claim, each told to refute it. Two rejections out of three and the claim dies. |
Synthesize | One agent merges survivors, ranks by confidence, writes the report with a note listing what got killed. |
The extraction step does not trust a webpage; it demands a checkable statement plus the quote that backs it. Verification is adversarial on purpose. If you wanted to teach someone how a research agent hangs together, you could do far worse than handing them this file.
Good skeleton.
The thing I couldn't stop looking at
Then I read the prompt the harness hands each searcher.
Every searcher is told to rank its results by relevance to the original question. The instruction is verbatim: "Rank by relevance to the ORIGINAL question, not just the search query." Every one of them starts from the same prompt the scoping agent wrote at second zero.
Nothing any searcher finds ever changes what gets searched. No agent reads a result, feels the tug of wait, that implies something, and forms a sharper question from it.
The orchestrator does not loop. Scope happens once. Search happens once. The report is built from whatever that single sweep dragged up off the seabed.
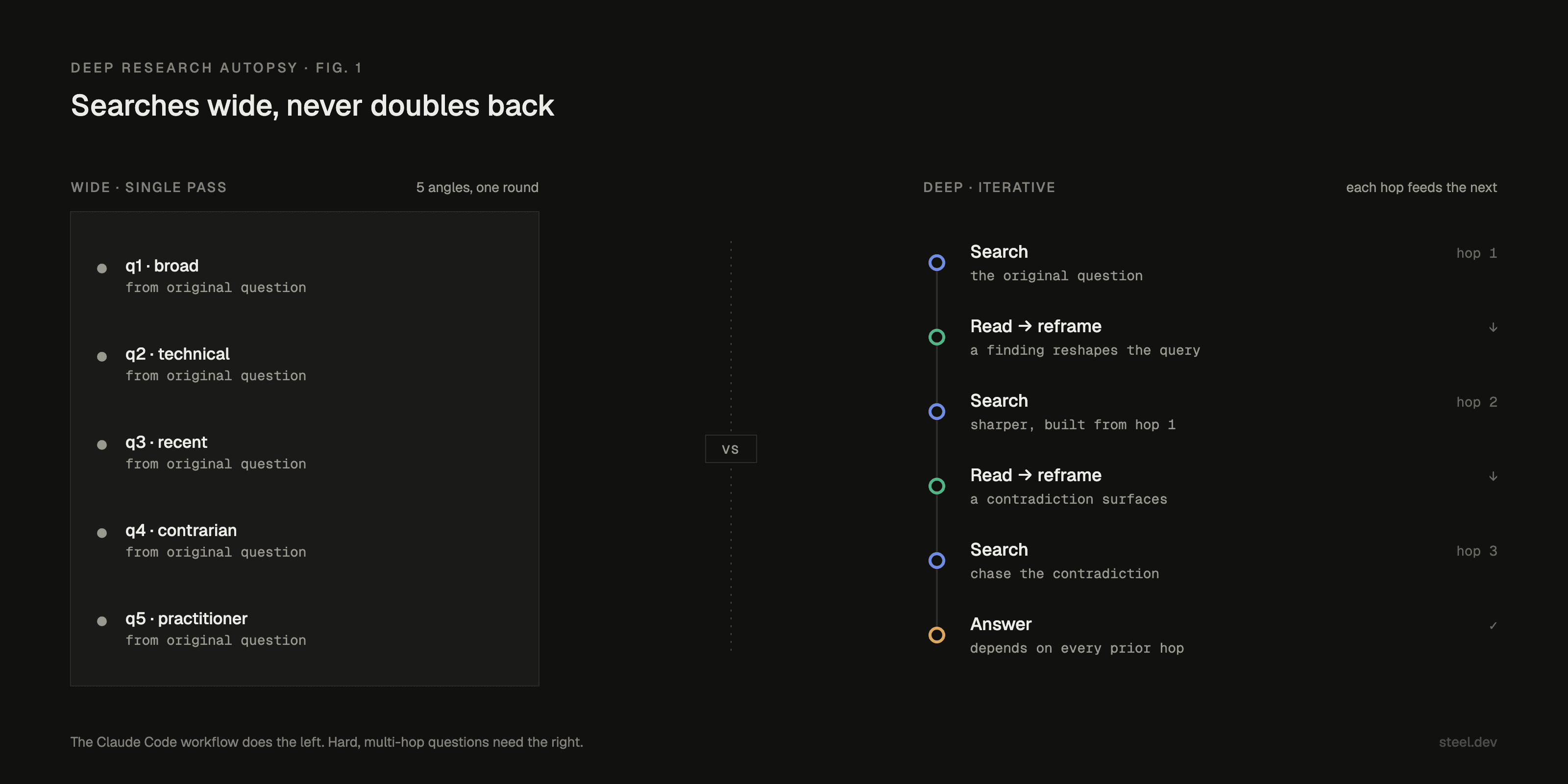
That is the gap between wide and deep, and it fits in one picture.

Think about how you actually research something that matters. You search, you read, and the reading rewrites the next question.
The answer to hop one becomes the input to hop two.
A genealogist hits a misspelled surname in a parish record and that misspelling becomes the next query. A reporter notices the dates don't line up and chases the dates.
Nobody writes five queries in advance and stops.
The reference harness cannot follow a thread. That is the missing second hop.
Then I checked whether the big hosted products do the same thing under nicer branding.
Where my theory fell over
They don't. I read their own engineering writeups, and almost every serious one is a hybrid: parallel fan-out inside a round, genuine iteration across rounds.
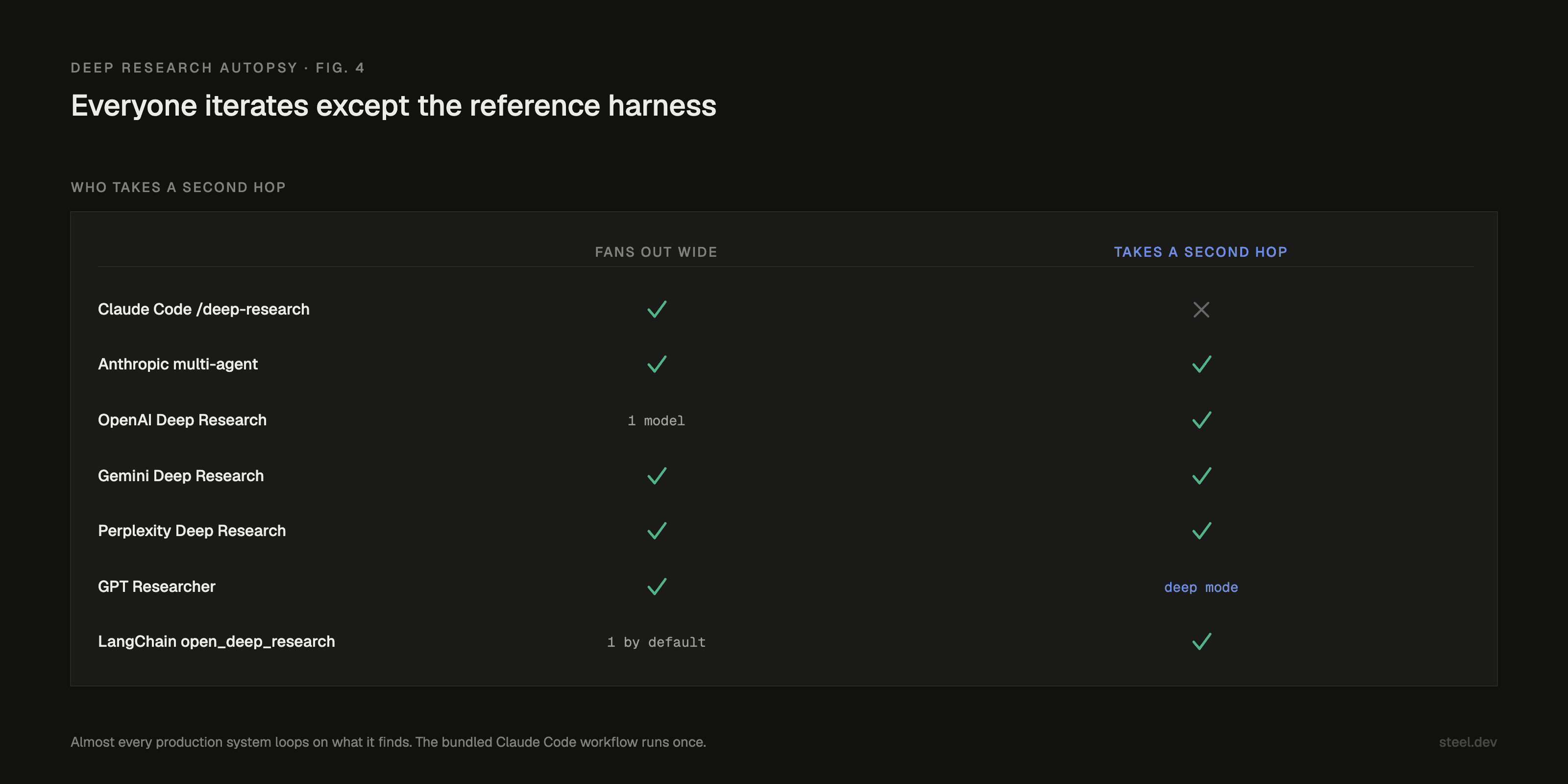
Anthropic's multi-agent research system looks like the most wide-open thing in the field: a lead agent spinning up three to five subagents in parallel rather than serially. But read the next sentence. The lead agent "synthesizes these results and decides whether more research is needed, and if so, it can create additional subagents or refine its strategy." That is a loop. Even the system that looks the most like a fan is iterating at the top.
The rest line up the same way:
OpenAI Deep Research is one reasoning model, trained with the same recipe as o1, browsing and "pivoting as needed in reaction to information it encounters." The second hop is baked into the weights.
Gemini ships an explicit "Plan, Search, Read, Iterate, Output" loop and calls itself "an iterative, multi-step system, not a single-pass model."
Perplexity "reasons about what to do next, refining its research plan as it learns more."
Open source splits down the same seam. GPT Researcher runs wide fan-out by default, then offers a separate recursive "Deep Research" mode for the tree. dzhng/deep-research puts breadth and depth right there as knobs and feeds each level's findings into the next level's queries. LangChain's open_deep_research goes the other way and tells its supervisor to "start with one sub-agent for most queries."
The freshest data point landed while I was editing this. Anthropic's Claude Fable 5 system card benchmarks three multi-agent harness shapes head to head on BrowseComp, and the one that most resembles this workflow, an orchestrator that fans out subagents and blocks until they all return, loses to both non-blocking designs on latency and tokens. Their diagnosis is structural: every round is gated by its slowest subagent, and each freshly spawned subagent pays to re-establish context. Even at the frontier, the barrier is the tax.
So "wide, not deep" is wrong as a description of the field. What survives is more precise:
The bundled reference harness is single-pass wide. The systems it superficially resembles are hybrid: wide within a round, deep across rounds. The whole difference is the second hop, and the second hop is the part that costs.
That last clause is the one I keep coming back to.
Why the reference stays shallow
Why one pass and not a loop? Three reasons:
Depth doesn't parallelize. A second hop has to wait on the first, so you forfeit the wall-clock win that makes fan-out attractive.
Depth rabbit-holes. Left to iterate, an agent chases a tangent through a dozen queries because nothing tells it to stop.
Width is legible. You can hold the whole pipeline in your head, which is exactly why it is the shape people copy.
And depth is expensive.
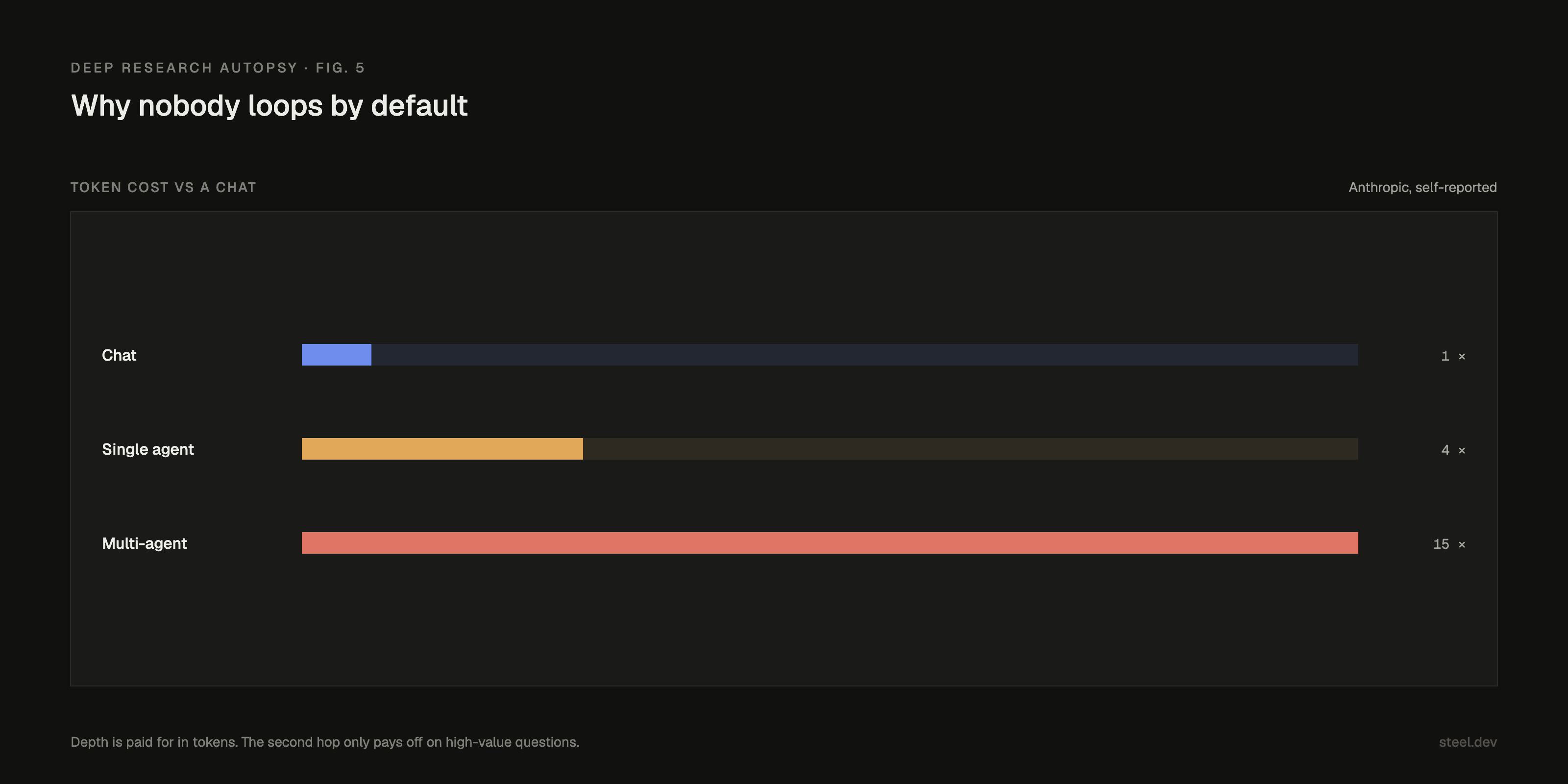
Anthropic reports that an agent burns roughly 4× the tokens of a chat, and a multi-agent system about 15×. Their multi-agent setup beat a single agent by 90.2% on an internal eval, but they concede it only pays off on high-value work. (Self-reported, internal, breadth-first. Take it as direction, not fact.)
A reference is built to be understood. Single-pass and wide is the most legible shape there is, which is why it is the one that propagates.
The limits of adversarial verification
The harness leans hard on verification to make up for shallow search: three skeptics vote on every claim, two rejections kill it. It is the most sophisticated part of the pipeline.
But majority voting only works if the three skeptics fail independently. Self-consistency earns its accuracy gains exactly under that assumption: sample diverse reasoning paths, let independent errors cancel. Recent work on deep-research agents finds the opposite. Their errors are correlated: "Errors arising in one run also tend to recur in other runs." When three skeptics share one blind spot, three votes is one vote billed three times.
So the two weaknesses are really one. The search is shallow, and the net built to catch its mistakes has the same holes the search does.
I pointed it at real questions
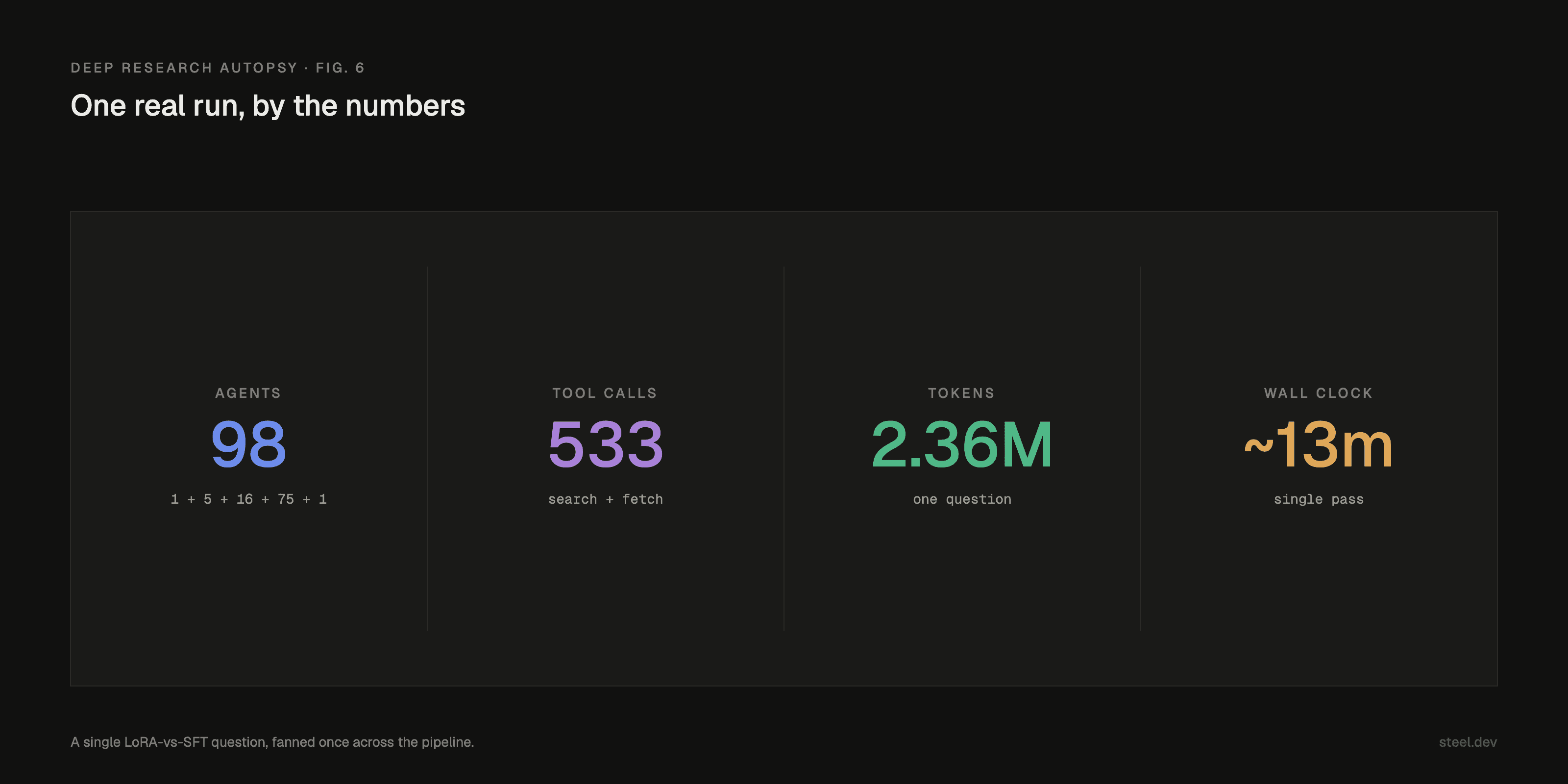
To watch the shape move, I gave the harness a genuine one: does LoRA match full fine-tuning for open models in the 7B-70B range? It ran for about thirteen minutes and spawned 98 agents: five searches, sixteen fetches, seventy-five verifiers, then synthesis.
The run was on Opus 4.8. We never logged the input/output split, so the bill is an estimate, but at list prices ($5 per million tokens in, $25 out) those 2.36 million tokens can't be cheap. For one question.
The verifiers earned their keep. They killed the "new variant nearly closes the gap" claims, the easy, independent failures a skeptic can refute with one contradicting source. You can watch the whole winnowing in one chart: sources breathe in, claims breathe out, the guillotine takes the rest.
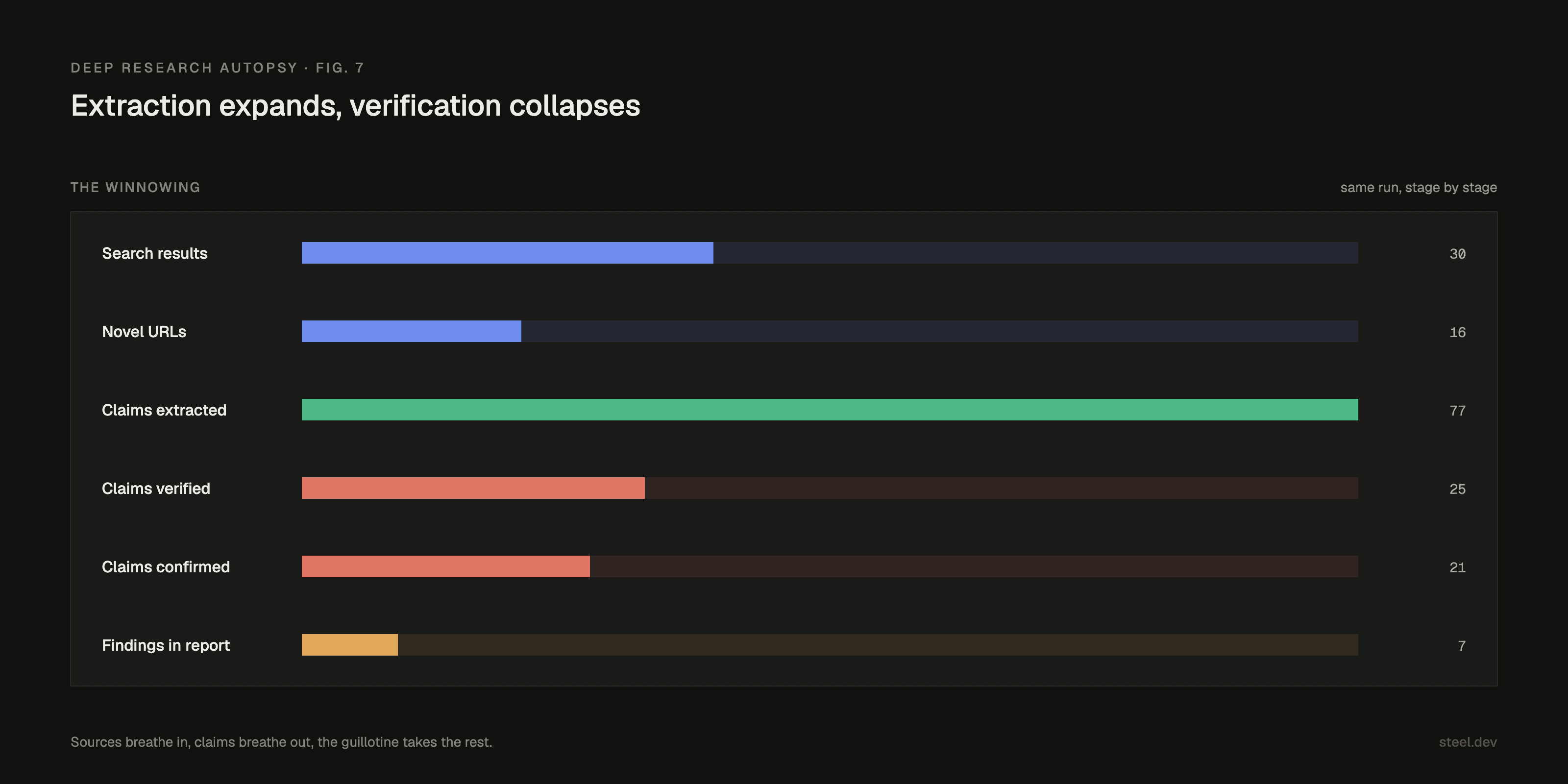
But the report also flagged its own gap: the 70B evidence is thin, and the strongest claims lean on a non-peer-reviewed blog. It saw the hole and had nowhere to put it.
A deep harness would have turned that caveat into the next query. This one moved straight to synthesis, because it has no next query to make. That is the missing second hop, on a real question.
Then I ran it on a question built to break it, a needle from Perplexity's DRACO benchmark: name the 5K race at California's old Great America park with "bubble gum" in its title. The answer hides in a homophone. Bubba Gump, the Forrest Gump shrimp brand, runs a "Run Forrest Run" 5K, exactly the suspiciously neat connection a single deep chain tends to find and then talk itself out of.
The harness got it, and for a structural reason. Four of the five parallel searches surfaced the homophone independently, so no lone reasoner had to trust a lucky hunch. The adversarial verifiers then kept the system from overclaiming that a shrimp brand "is" bubble gum. What it wrote was careful: the premise has a homophone error, here is the real race, medium confidence.
That careful answer is what width and skepticism produce when they fight each other. Sometimes the fan is exactly the right shape.
The Fable 5 system card puts numbers on when. Multi-agent teams posted Anthropic's highest BrowseComp score (93.3%), but the gain lives almost entirely in the hard tail: on problems most models already solve, the median multi-agent speedup was 0.8×, slower than one agent, because coordination overhead eats the parallelism.
Width is neither a free lunch nor a scam. It is a bet that your question sits in the hard tail, and the needle questions do.
What I'd tell someone building one
Know which pattern you started from. Most research agents begin life as a copied reference implementation. Ship the Claude Code deep-research shape unchanged and you ship single-pass width: cheap, fast, legible, and blind to anything that needs a second look.
Match topology to difficulty. Go wide when the angles are independent and the answer is a synthesis of parallel facts. Pay for depth only when the next question genuinely depends on the last answer.
Budget for the second hop. When you go deep, expect serial latency, a ~15× token bill, and a verification layer that must assume its own votes are correlated.
The frontier is not more width. It is a disciplined second hop: knowing when to take it, when to quit, and how to trust what you find. Nobody has cleanly solved that. It is the part we are building toward.
The harness proved its own ceiling for me. I watched it research this exact question, fan my prompt five ways, and never look back at what it found.
So I built the deep version: a research agent that routes before it searches, browses before it loops, and verifies its own claims. It got worse before it got better. The verifier I was proudest of dropped my report quality, and it took me a while to work out why. That is the next piece: Durable Researcher: building a research agent that survives its own failures.
I'm still thinking about the second hop. But now I have one.


All Systems Operational