

I have been fascinated by deep research agents for a while now, studying every shape I stumble on.
In part one I took apart the deep-research harness inside Claude Code. This is what happened when I built my own and pointed real evals at it. Then rebuilt it.
TLDR: Durable Researcher is a browser-native deep research agent that checkpoints every model step, rebuilds state from the transcript, routes tasks by answer shape, and uses eval failures as the product loop.
The point was to make every failure leave enough state behind that I could resume it, inspect it, and turn it into the next change. Make a better agent.
The first version was good at the wrong thing.
It wrote beautiful overviews. It planned sub-queries, browsed in parallel, took notes, checked its coverage, and produced a polished report. Ask it to survey a field and it shined. Ask it for one number, like a cash-flow figure from a filing, and it handed you a thoughtful essay about the company instead.
So I added a citation verifier. It checked every claim in the report against the agent's notes and triggered a rewrite when the evidence was thin. Clean. Obviously the kind of thing a research agent should have.
The evals said it made things worse. I switched it off.
Build what seems right. Test it on real tasks. Read the failures. And when the data turns on you, quarantine your cleverness until you understand it.
The Durable Research Loop
Durable Researcher takes a topic, plans sub-queries, runs them in parallel against real browser sessions on Steel, takes structured notes, checks its own coverage, fills the gaps, and writes a report.
Steel matters because the agent needs browsers, not HTTP fetches. The useful research lives on pages that render late, redirect, block scrapers, or hide their content behind behavior. A plain fetch sees none of it.
Every model message is checkpointed to Postgres as it happens. If the agent dies, the next run resumes from the last checkpoint. The model never knows it crashed.
That is only the first layer. Notes, visited URLs, claims, and source ledgers rebuild from the transcript. Scraped pages are cached in Postgres, keyed by task and URL, so a crash does not mean paying Steel to browse the same page again. Verification attempts are checkpointed too, which means a bad rewrite leaves a trail: claim verdicts, pass rate, unsupported lines, and reasons.
The stack: Bun and TypeScript, Pi for the agent loop, Absurd for durable execution, Steel for browsers, Postgres for persistence, a GLM-5.1 (cheap, fast and smart) model for reasoning, and Ink for the terminal UI.

None of it is exotic. The product lives in the fit between the pieces.
Campaign mode pushes the same idea further. Long research runs are split into bounded pulses, each with its own task ID, objective, report, judge decision, usage, and source inventory. That avoids one giant long conversation while preserving the user-visible behavior of one continuous run.
Part one found Claude Code's harness stuck in a single-pass pattern: scope once, search once, never let a finding change the next query. Mine had the same limitation until I taught it to take the second hop, which is most of what follows.
The Numbers, With the Caveats Up Front
There are two useful academic benchmarks for this kind of system. ResearchRubrics, from Scale AI, has 101 tasks with weighted criteria judged by an LLM. DRACO, from Perplexity, has 100 tasks with a similar shape.
Benchmark | Judge | Tasks | Score | How to read it |
|---|---|---|---|---|
ResearchRubrics | Gemini default | 10/101 |
| Promising, partial |
DRACO | Gemini 3.1 Pro | 10/100 |
| Paper-comparable, weak sample |
For reference, the published full-set ResearchRubrics scores are Gemini Deep Research at 61.5%, OpenAI Deep Research at 59.7%, and Perplexity Deep Research at 48.7%.
The judge belongs in the headline of the metric. LLM-as-judge numbers are useful, but only if every chart clearly says which judge produced them.
So the honest claim is narrow: promising on ResearchRubrics, lower-middle on the Gemini-judged DRACO sample. The full 100-task DRACO run still matters most. But for speed of the loop I have opted for a random 10% subsample.
Sprint One: Make Failure Resumable
The first sprint built the substrate.
Every assistant message becomes a step in the durable engine. On resume, the engine replays the completed steps and hands the conversation back to the model. There is no notes table. No visited-URL table. Tool calls and their results live in the message log, and the app rebuilds notes and URLs by walking it.
The transcript is the canonical artifact. If the log replays, the state replays.
The browse cache was the second practical piece. When a page has already been opened for a task, the content is stored with its title and raw length. On resume, the agent can reuse that page instead of pretending the crash erased the web it already saw.
That mattered more once verification entered the loop. The verifier needs source excerpts, not just a final markdown report. After a crash, the in-memory excerpt store is empty, so the agent rebuilds it from cached browse content before checking claims. Without that, a resumed run could have the right sources in its history and still fail its own citations.
On top of that I built the research loop.
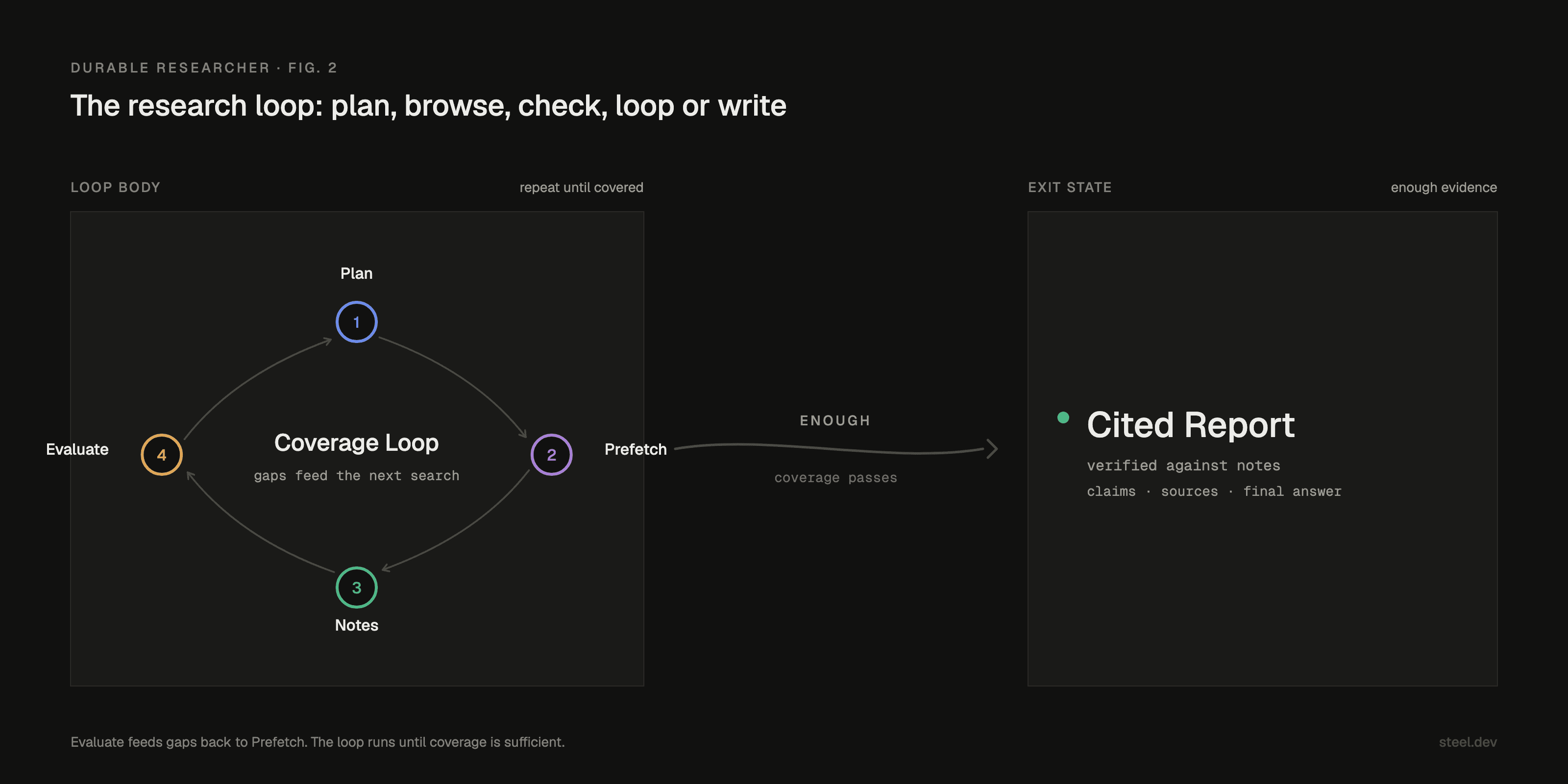
Planning produces sub-queries. Prefetch fans them out through Steel, searching and scraping the top results for each one in parallel. The agent reads the sources, takes structured notes, and calls an evaluation tool that summarizes coverage. Weak coverage, search again; good coverage, write.
The early version failed in boring, specific ways.
A broad query about agent-driven web automation came back with WhatsApp pages, German dictionaries, and a recipe site. The failure was retrieval, not browsing, so I added ranking signals for topic fit, URL paths, and domains that should never win. Bad candidates should lose before the browser spends time on them.
The additional tweak was to lean into what the model already knows: if we already know a relevant URL, browse it directly before searching again. Searching the open web before visiting one lets SEO fight your research before the agent has read the obvious page.
Another failure mode: search loops. The agent would fire seventeen searches in a row, tweaking keywords each time, browsing nothing. Every search cost money and taught it almost nothing.
The fix was simple: no more than two searches in a row without a browse. The exact number mattered less than the behavior it named. Searching without browsing is reading the card catalog and never opening a book, and the prompt had to say so.
Both rules are one rule with two faces: take the second hop. Read something and let it change what you do next, instead of firing another query into the dark. The Claude Code harness I took apart in part one never takes that hop. Most of this project was teaching mine to.
I built the eval harness too. It downloads the DRACO and ResearchRubrics benchmark datasets, runs the agent as a subprocess per task, and judges the output with an LLM. Multiple judges. Batch APIs where they exist.
The harness changed how I read metrics. Once I saw how far a score could swing on the judge alone, I stopped trusting any single number.
The Diagnosis
After the first sprint, I had Codex review the eval outputs on its own. It named the problem better than I had:
Durable Researcher was a good synthesizer with weak routing into exact lookup, primary-document extraction, and precision answering.
Exactly right. The agent nailed "write me a thoughtful overview of X." It flubbed "what was Apple's free cash flow in fiscal Q3 2024?" It used the same report-writing shape for both.
The roadmap was:
classify the task before planning
use a different first turn for exact tasks
build a real path to primary documents
produce an evidence table before prose for extraction tasks
gate completion on whether required values were actually captured
adapt the output style to the task type
Acting on it took me weeks. Routing was an architecture change.
Sprint Two: Route Before You Research
The second sprint started from one premise: the first turn matters more than another tool.
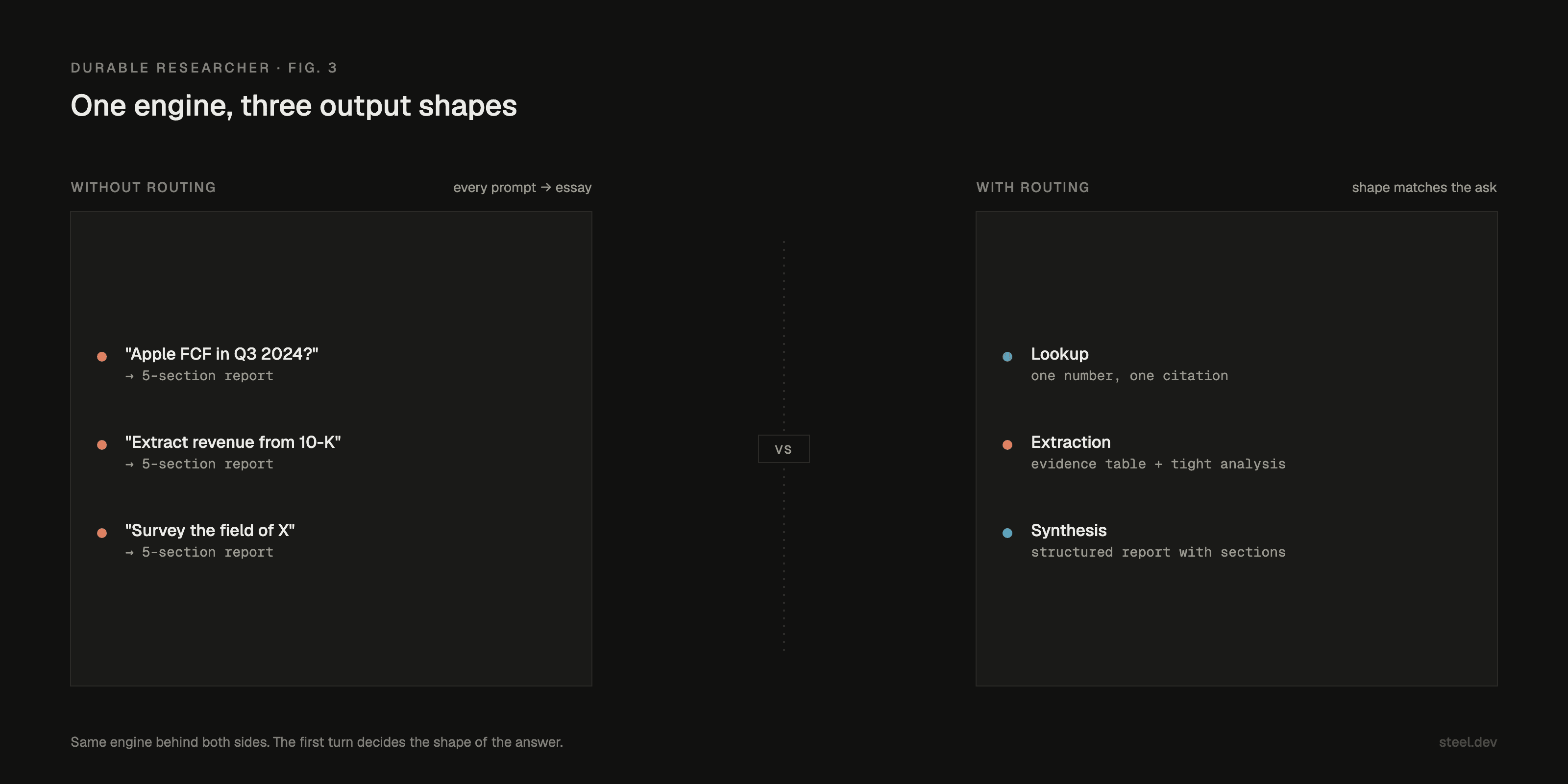
Before planning, the system now classifies the prompt as lookup, extraction, or synthesis. The mode picks the report template and the stop condition.
Lookup answers first and cites one strong source.
Extraction produces an evidence table as the deliverable, with tight analysis underneath.
Synthesis keeps the original report shape.
I added primary-source paths too. Financial and extraction-heavy queries needed a way to reach source documents instead of drifting around the open web. PDF text extraction handles the investor reports that normal scrapers turn to garbage.
It exposed a harder truth: having the path is not enough. The agent has to choose it at the right moment.
The Citation Verifier That Made Things Worse
The verifier was supposed to be the easy quality win.
After the report was written, the system parsed every citation, found its source, pulled the supporting notes, and asked a utility model one question: do verbatim excerpts back this claim? If the pass rate dropped below a threshold, it injected a steering message and let the agent rewrite.
Each verifier attempt was committed as its own checkpoint, with the claim verdicts, pass rate, cited source numbers, and failure reasons. That made the autopsy much less mystical.
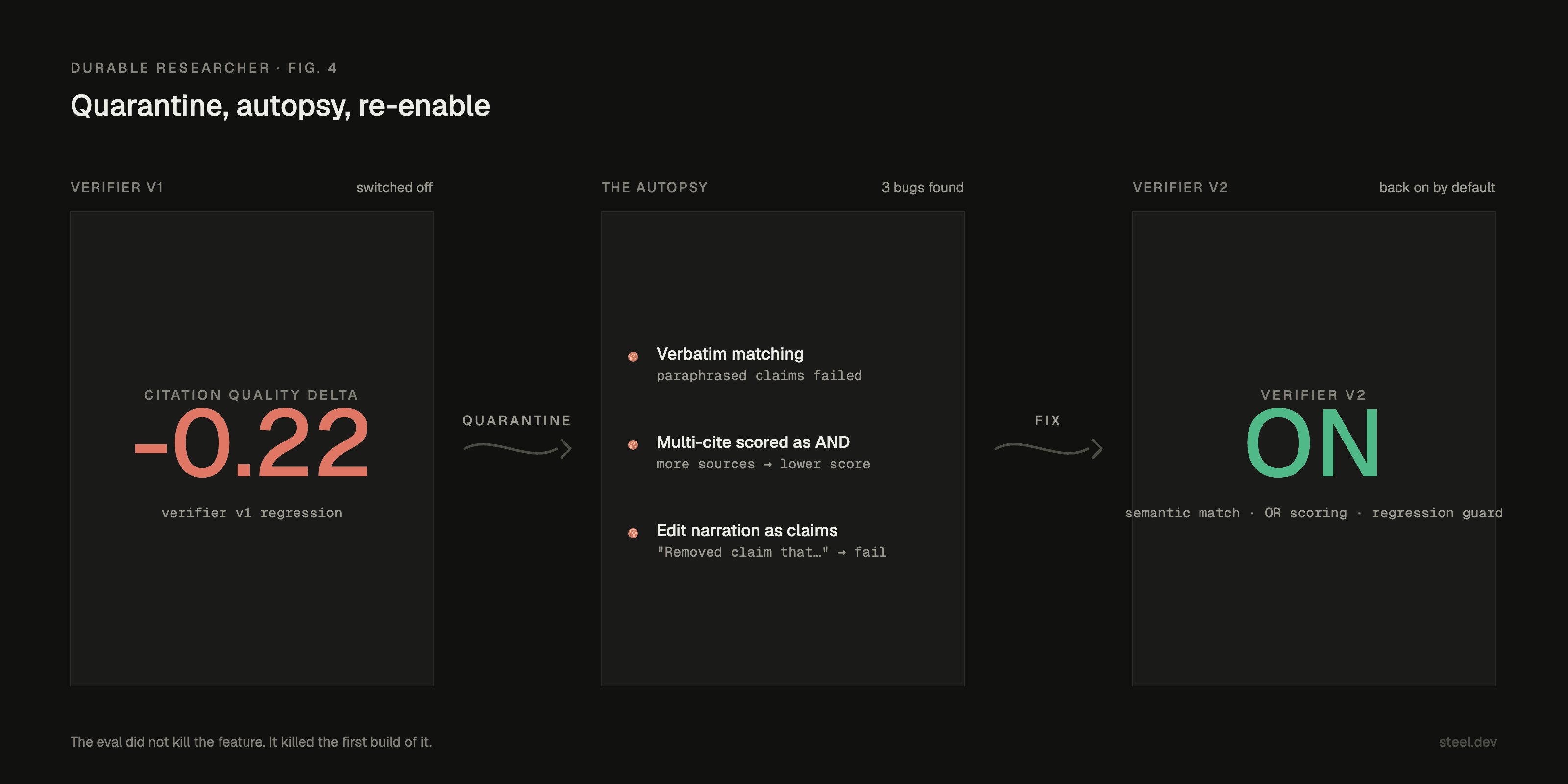
On a small eval comparison, citation quality fell by 0.19 to 0.22 absolute points on a 0-1 scale.
This was the same lesson one layer down: a verifier can make a system worse when its failure mode is correlated with the writer's. The lensed query expansion I had added in the same sprint, which generated definition, recency, criticism, and primary-source angles for every sub-query, was dragging the system toward tutorials and news.
The hotfixes were predictable. Source-authority weighting. Stronger source-selection prompts. The extraction heuristic. Peer-reviewed and government domains up, PR wires and thin aggregators down.
Learning: keep measurement on, but make losing behavior easy to switch off.
The rewrite was not wrong in principle. My implementation had specific, findable bugs. Blame it on the agent.
So I fixed the verifier, not the writer: semantic matching, OR scoring for grouped citations, edit-narration stripping, a best-version guard, and a skeptic refuter at the decision boundary.
Then I turned it back on by default.
The real lesson is: switching the losing build off gave me room to see why it lost.
Sprint Three: When The Question Is The Hard Part
Routing decided what kind of answer to produce. It did not help when the question itself was hard to interpret.
Some questions are disguised: a homophone, a paraphrased proper noun, or a reference buried in a casual phrase. The old planner decomposed every topic along literal research lenses, so a question in costume got searched at face value and never cracked.
Now the planner reasons about the question before it writes a single query. It lists explicit interpretations, decodes the oblique reading, and searches both the literal and the lateral version. It treats the user's stated details as fallible clues, because people misremember and approximate. And it carries a needle prior: if a question is dressed up as hard but its literal phrasing would be trivial to search, the surface reading is probably a decoy, and the lateral readings get the weight.
One bug from that work shows how these systems leak.
The planner generated the interpretations correctly. A downstream parser dropped the field before it reached the agent, and the renderer never showed it. The lateral reasoning was real, then silently thrown away. Wiring it through changed the agent's behavior more than any prompt line did.
The next problem was subtler, because it sounded like good judgment. A single reasoning chain would reach the right answer and then talk itself out of it.
On one homophone needle in the haystack problem (love the "Run Forrest Run 5k" one), the agent found the correct answer, decided it was too cute to be real, and dropped it.
Re-rolling the same chain is not a second opinion. The same model with the same framing tends to fall into the same hole. A second opinion only helps if it can fail differently from the first.
The fix was redundancy, not a better prompt. Several workers now attack the same question from different readings, each told not to self-reject, and their evidence pools so independent agreement builds into confidence. A full extra agent gets spent only on a top answer nobody has confirmed yet.
Then a separate adversarial pass judges whether the answer is correct, which is a different question from whether a citation is grounded. Skeptics vote. Abstentions are safe. Refuted answers stay in the report as a transparency block instead of vanishing.
On the needle that started all this, the chain now surfaces the right answer and lands at medium confidence with a caveat, instead of confidently wrong or confidently silent.
The last piece was depth. Routing made lookups short, which exposed the opposite problem on broad synthesis: reports that were accurate and thin.
Survey mode runs several research passes and merges them deterministically into one report, with a single global source list and every citation marker remapped to match, then spends one constrained model pass on the prose. A gap-fill loop and citation chasing push for density instead of letting the writer quit early. On by default.

Make Agent Work Visible
At first the CLI was a wall of logs. Long stretches of nothing, and no way to tell whether the agent was thinking, browsing, stuck, or dead.
So I built a terminal UI: findings, activity stream, agent status, a token meter, streamed assistant text between tool calls, per-tool progress, a verification indicator. Once the browser work ran through Steel, the UI had to show those sessions too: searches launched, pages opened, scrapes done, failures returned.
The real win is steering. You can type a redirect mid-run, and it lands as a tagged user message before the next model turn. The system prompt teaches the model how to treat it.

The Dogfood Loop
The most productive workflow was not complicated:
Run the agent on a real, non-trivial topic.
Read the full log (feed it to the coding agent).
Compare the saved report against the scraped pages and task rows in Postgres.
Name each problem in one sentence.
Write a failing test.
Make the change.
Read the diff back as a hostile reviewer.
Fix what the review finds.
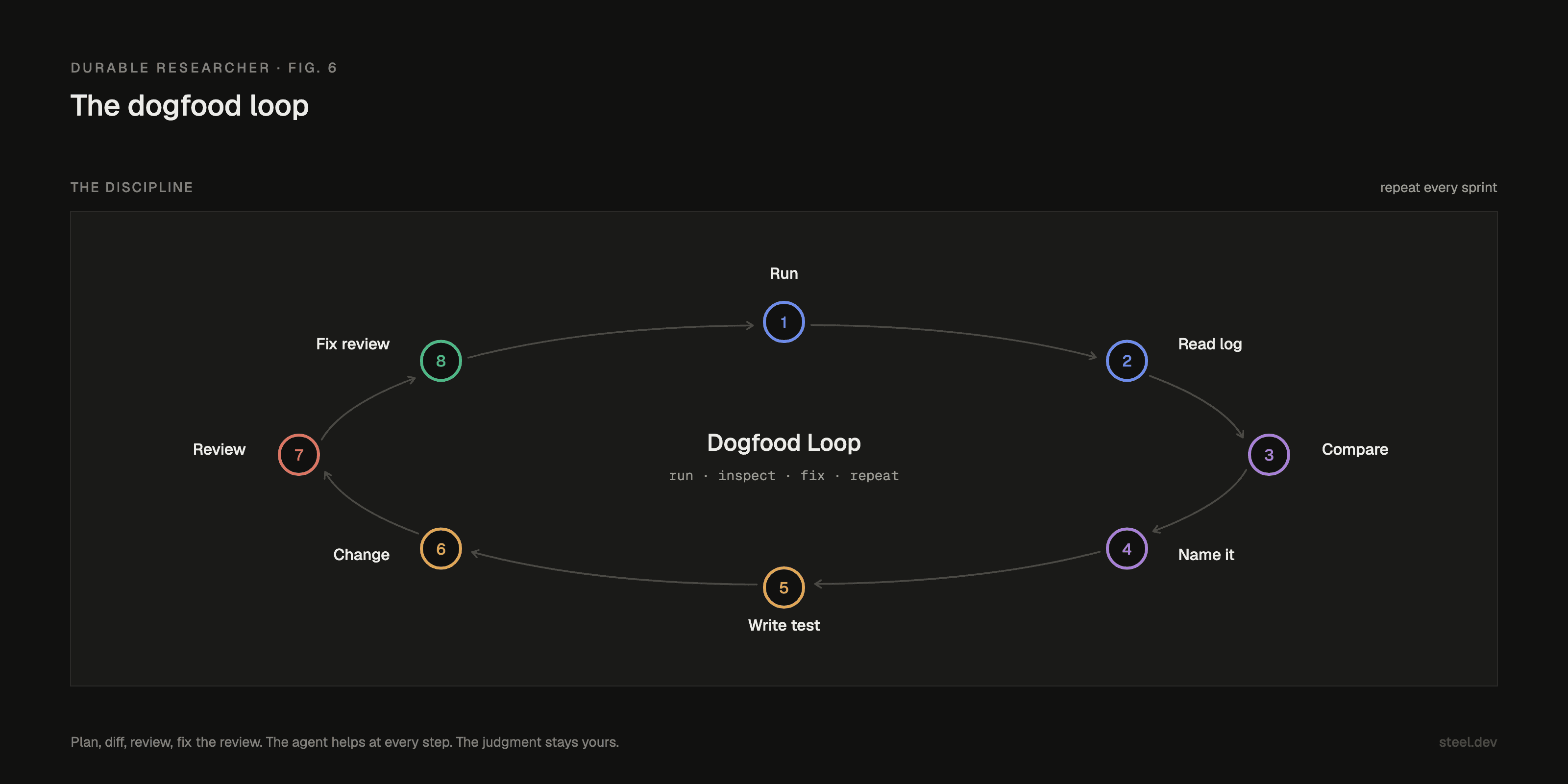
That became the discipline: plan, diff, review, fix the review. The agent helps at every step.
What Stuck
Routing beats tooling. The biggest quality lift I saw came from deciding what kind of task the user asked for before running the loop. Some prompts want a number, some a table, some a report.
Width and depth are tools, not maturity levels. The useful system routes first, then spends parallelism, iteration, or neither based on the shape of the question.
Durability works when the transcript is enough. Store tool-derived state anywhere else and you end up with a second source of truth. If notes, URLs, claims, and verifier context rebuild from committed messages and caches, crashes become annoying instead of existential.
Browser infrastructure is product infrastructure. For a research agent, the browser is not plumbing. It decides what the model can know, and the evals only matter if they test the system against that reality.
The Same Discipline Applies
Building one agent with help from another collapsed the line between product and tool.
Reading the research agent's outputs carefully turned out to be the same discipline as reading the coding agent's diffs carefully.
Make the work visible. Route before acting. Refuse cheap fixes. Retire features when the evidence turns on them.
Ask me again after some more work lands. Something else will have failed by then, and that is the point.
Find the Experiment
The code, tests, eval harness, and vibes are here: steel-experiments/durable-researcher.
It is not the final production shape. It spends tokens like it found a company card. But it survives its own failures now, and that made it finally worth improving.


All Systems Operational