Atlas: a deep research harness you can own
Atlas: a deep research harness you can own
Atlas: a deep research harness you can own
/
/
San Francisco
San Francisco
/
/

JunHyoung Ryu
JunHyoung Ryu

Launch Week v3 -> Day 04 / 05
Atlas is an open-source deep research harness you can run, fork, and bend around your own domain. It gives you the loop in one SDK: ask a question, gather evidence across the open web, and get back a cited report. Before it lands, Atlas checks the draft against the ledger and grounds the citations.
The job is simple: stop every team from rebuilding the same brittle research loop, while leaving the knobs exposed. Swap models, search providers, browser fetches, and domain sources.
This is the next step in Launch Week v3: Stealth Browser for the browser runtime, Dedicated IPs for stable network identity, Rust and Go SDKs for the services doing the work, and Atlas for the research layer.
Install it:
npmnpmThen bring your model provider, wire in search or browser fetches, and start shaping the loop around your domain.

Why deep research is hard to build
A lot of teams are putting deep research agents inside their products. Some already use Steel for the browser side. The painful part is everything around it: planning the search, keeping sources straight, tracking what’s still unanswered, and staying inside a budget.
The common failure is quieter than a fake source. A long run reads a pile of pages, the early evidence gets summarized away, the writer drops a real fact it found twenty turns ago, and the final report looks clean while quietly missing the thing you asked for. Atlas is built around that failure.
How Atlas works
A single run is a loop built around a ledger.
The ledger is a coverage contract. Atlas breaks the question into slots: the things the answer has to cover. A slot pairs a question with its eventual grounded finding. Atlas strips numeric literals out of slot phrasing, so the planner has to earn the answer from evidence. As evidence arrives, each slot becomes grounded, computed from other slots, or marked exhausted with a reason.
The run moves through the ledger like this:
Plan. Seed the ledger with slots from the question.
Gather. A research agent searches, fetches, and reads, closing slots as it lands grounded answers.
Synthesize. Write the full report from what’s been gathered.
Audit. Walk the draft back against the ledger and find the gaps: open slots, facts the writer gathered then dropped.
Patch and reconcile. Fetch what’s missing, fill the gaps, then a final pass using only sources already in the store.
Ground. Renumber every citation, validate that each
[n]points at a real fetched source, and surface any sentence whose citation doesn’t hold up.
The audit step is where the ledger pays for itself. Atlas checks the finished draft against what it meant to answer, then catches dropped facts, unanswered slots, and citations that point nowhere. Because grounding happens last, the result includes result.unsupportedSentences: the sentences whose citations did not survive.
How it scores on DRACO
DRACO is Perplexity's open deep research benchmark: 100 real-world tasks across 10 domains, each graded against ~39 weighted criteria where wrong answers count against you. We ran a simple setup of Atlas on it next to the commercial agents.
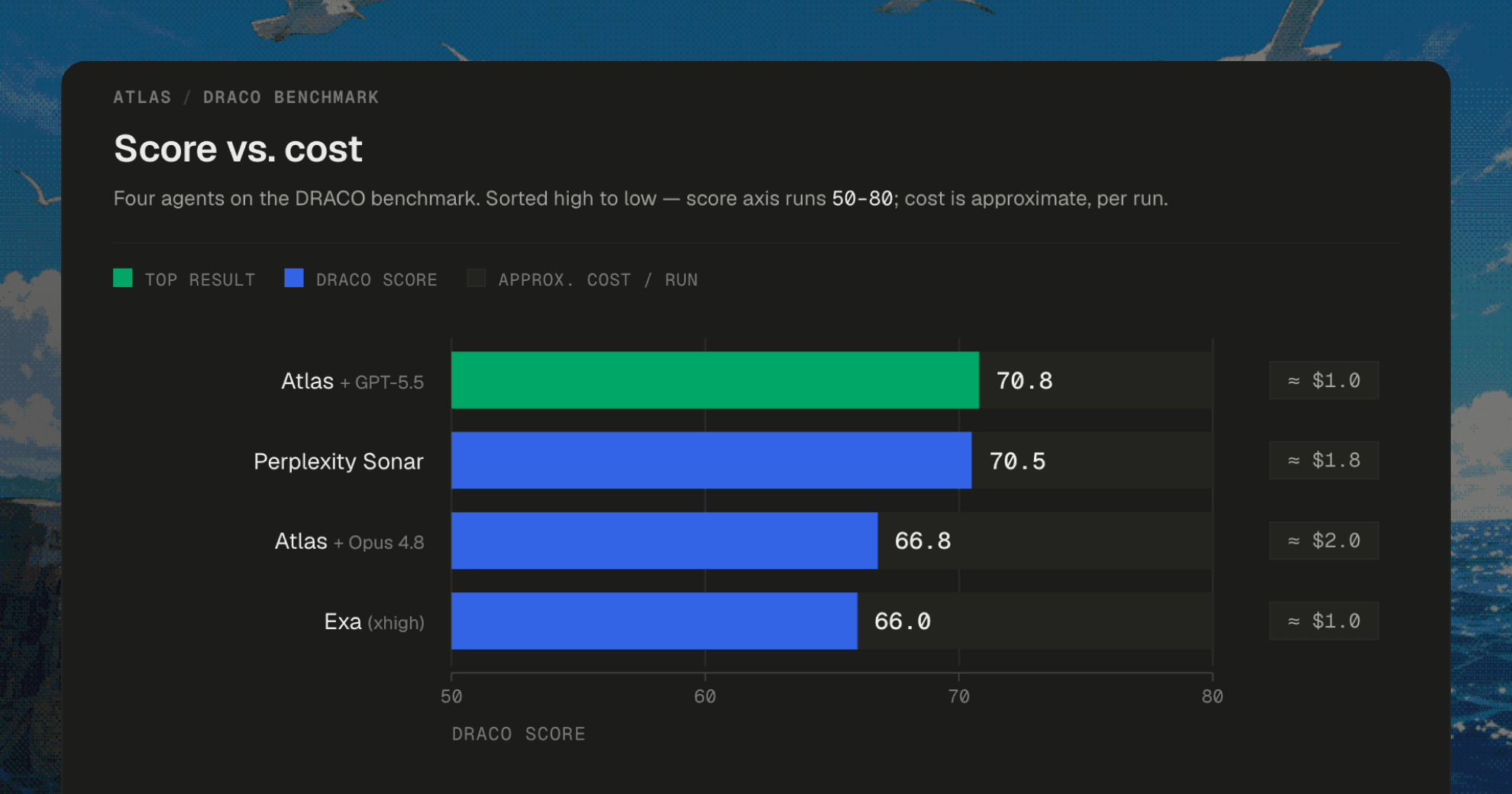
The band is tight. Atlas on GPT-5.5 lands level with Perplexity Sonar, a hair above on Perplexity's own benchmark, and at lower cost. Atlas on Opus 4.8 sits next to Exa. Nobody runs away with it.
That is the point: an open harness you can fork and aim at your own sources scores in the same range as the closed products, not a tier below them.
Watch one run
Here’s a real run: Claude Opus 4.8 at balanced effort, reading a single SEC filing. The question asks Atlas to analyze a margin shift and adjust it for a one-time relocation loss:
Analyze how Rubber Leaf’s strategic shift from direct to indirect supply models has affected underlying profitability by examining gross margin performance across Q1 2023 and Q1 2024 […] then determine what Rubber Leaf’s Q1 2024 gross margin would be when excluding the factory relocation loss from total cost of sales.
Atlas turned that into a 15-slot ledger. A sample:
ask | shape | importance |
|---|---|---|
Year-over-year change in gross margin from Q1 2023 to Q1 2024 (in percentage points) |
| central |
Rubber Leaf’s adjusted Q1 2024 gross margin excluding the factory relocation loss |
| central |
How the indirect supply model alters cost structure and margin economics versus the direct model |
| central |
Verdict on whether margin pressure is driven by fundamental challenges in the indirect model or by temporary relocation costs |
| central |
Other one-time or non-recurring items affecting Q1 2024 cost of sales beyond the relocation loss |
| peripheral |
The asks avoid guessing the values. They name what Atlas has to establish. Each one closes as grounded with a value, quote, and source, or computed with run_code or synthesis across sources.
The report starts with the computed result: gross margin fell from +2.86% to -6.65%, a 9.52-point drop. Stripping out the $190,703 one-time relocation loss lifts it only to -0.20%. The more interesting part is what the run caught on the way:
the 10-Q’s MD&A “Gross profit margin” table states Total margins of 7% (2024) and 3% (2023) […] Those stated percentages do not reconcile with the negative gross profit reported on the company’s own income statement and appear to be a misstatement; the analysis below uses the gross profit and revenue figures from the consolidated statement of operations.
Atlas caught the contradiction in the filing and recomputed from the primary statements.
The whole run took about four minutes, and zero sentences failed citation grounding:
phase | time |
|---|---|
seed (ledger) | 9.8s |
gather | 89s |
synthesize | 44s |
coverage audit | 5.8s |
patch | 24s |
reconcile | 16s |
Three pages fetched, one cited, the filing itself.
Orchestrate researchers
By default, a run follows one spine. When a question needs more than one angle, you can register multiple researchers. Atlas decomposes the question, routes each sub-task to the best-fit worker (query → report), runs them in isolation, then synthesizes one cited report.
Any query → report worker plugs in: Exa deep research, Perplexity Sonar, parallel.ai, or your own. atlas.asResearcher(describe) exposes an Atlas instance as a worker, so fan-out can recurse. Omit researchers and Atlas stays on the single-spine path.
Uses Steel for browser fetches
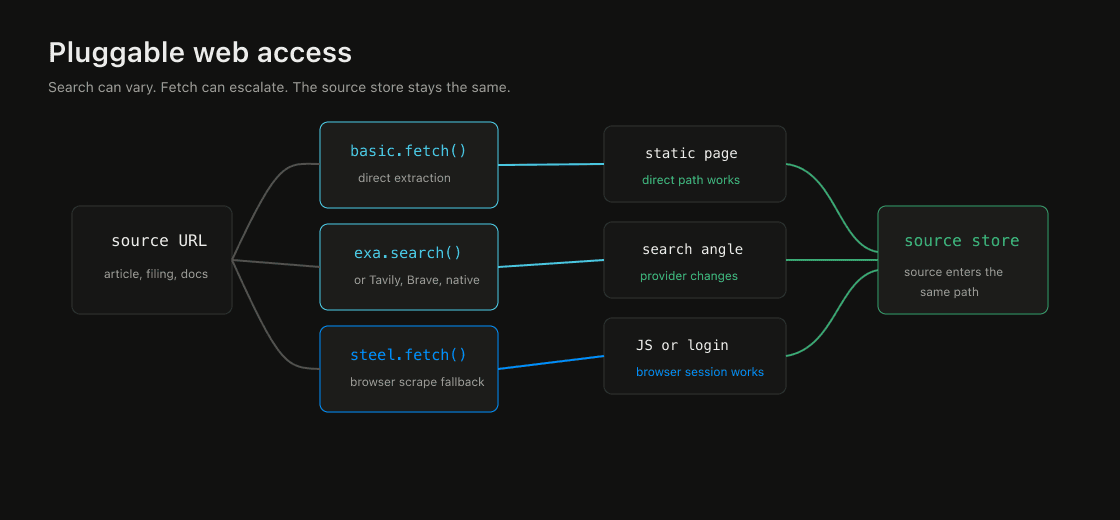
Atlas can use Steel for browser fetches, so the loop reaches pages a basic fetch misses: JavaScript-rendered sites, sessions that need login state, pages that need a real browser to stay alive long enough to be useful.
Atlas can start with direct extraction and fall back to a Steel browser scrape when the page needs it. Search can come from Exa, Tavily, Brave, or the model provider’s own web search, so a run can use more than one source path.
The parts builders ask about
A single model runs everything. If you want more control, override research and write; unset roles fall back to the lead model.
Every model goes through the same wrapper: budget accounting, retries, caching, tracing, and the provider quirks that would otherwise leak into your code.
It keeps a trail. Atlas records searches and dead-end fetches so a later step can pick a new angle after a query goes nowhere. The trail is a plain record of what already wasted time.
It streams. Start a run and subscribe to events: report.delta carries the draft as it’s written, report.reset precedes each rewrite, source.fetched fires as pages come in. Await the final result when you want it.
It resumes. Journaled runs replay completed model, search, and fetch calls at no cost after a crash or deploy.
It returns structured output. Pass a schema and Atlas runs a final extraction pass over the finished report. You get a typed object alongside the markdown, on the single-spine path or the orchestrated path.
Safety
Atlas treats untrusted web content as data. Fetches pass SSRF guards. run_code runs in a memory-capped V8 isolate with no network, filesystem, or host access. Direct fetch honors robots.txt. Treat the SSRF guard as defense-in-depth; for hostile targets, run behind network-level egress controls. The README has the full picture.
Built with agents
Most of Atlas was written through AI pair-programming. The structural decisions are human: the shape of the loop, where the audit sits, what the ledger holds. The code came fast. The hard part was choosing what lives outside the model: the ledger, the budget meter, the trail of searches, the point where the run stops and checks its own work.
Built for verticals
Generic research tools hit a ceiling fast. Atlas is meant to be extended into a domain: a finance researcher that reads filings, a health researcher that works through clinical literature, a workflow with its own weird sources and review rules.
researchTool is for that. If the right source is EDGAR, PubMed, arXiv, OpenAlex, ClinicalTrials.gov, or your internal docs, wire it in directly; anything you add through ctx.addSource flows into the same source store, the same report, and the same grounding pass.
For a full example, the Atlas public company research demo shows the pattern applied to public biotech research with SEC filings, trial registries, PubMed, and optional Steel browser fetches.

Where Atlas needs care
Atlas grounds and audits. Weak sources still produce weak evidence; paywalled, missing, or contradictory sources still need a human’s judgment. The better you know your domain’s sources and failure modes, the better you can tune Atlas around them.
It also costs real money. A balanced run targets a couple of dollars, so runs need explicit budgets and caps. maxUSD is a best-effort target; provider calls can still land above it. If you bring a custom model, pass its pricing so the budget math stays honest.
Before you spend real money tuning a vertical, use the Browser Agent Leaderboards to narrow the model list. DRACO is the closest fit for Atlas because it grades full research reports across 100 expert-scored tasks, not short answers. Treat it as a filter, not a verdict: each row mixes a model, harness, judge, budget, and tool setup.
Get started
Install:
npm install @steel-dev/atlasPackage: @steel-dev/atlas on npm
Public company research demo: a biotech-company memo workflow using SEC EDGAR, ClinicalTrials.gov, PubMed, optional web search, and optional Steel browser fetches.
Questions? Discord or @steeldotdev.
This post is Day 4 of Steel Launch Week v3. See the full week at steel.dev/launch-week.
Launch Week v3 -> Day 04 / 05
Atlas is an open-source deep research harness you can run, fork, and bend around your own domain. It gives you the loop in one SDK: ask a question, gather evidence across the open web, and get back a cited report. Before it lands, Atlas checks the draft against the ledger and grounds the citations.
The job is simple: stop every team from rebuilding the same brittle research loop, while leaving the knobs exposed. Swap models, search providers, browser fetches, and domain sources.
This is the next step in Launch Week v3: Stealth Browser for the browser runtime, Dedicated IPs for stable network identity, Rust and Go SDKs for the services doing the work, and Atlas for the research layer.
Install it:
npmThen bring your model provider, wire in search or browser fetches, and start shaping the loop around your domain.
Why deep research is hard to build
A lot of teams are putting deep research agents inside their products. Some already use Steel for the browser side. The painful part is everything around it: planning the search, keeping sources straight, tracking what’s still unanswered, and staying inside a budget.
The common failure is quieter than a fake source. A long run reads a pile of pages, the early evidence gets summarized away, the writer drops a real fact it found twenty turns ago, and the final report looks clean while quietly missing the thing you asked for. Atlas is built around that failure.
How Atlas works
A single run is a loop built around a ledger.
The ledger is a coverage contract. Atlas breaks the question into slots: the things the answer has to cover. A slot pairs a question with its eventual grounded finding. Atlas strips numeric literals out of slot phrasing, so the planner has to earn the answer from evidence. As evidence arrives, each slot becomes grounded, computed from other slots, or marked exhausted with a reason.
The run moves through the ledger like this:
Plan. Seed the ledger with slots from the question.
Gather. A research agent searches, fetches, and reads, closing slots as it lands grounded answers.
Synthesize. Write the full report from what’s been gathered.
Audit. Walk the draft back against the ledger and find the gaps: open slots, facts the writer gathered then dropped.
Patch and reconcile. Fetch what’s missing, fill the gaps, then a final pass using only sources already in the store.
Ground. Renumber every citation, validate that each
[n]points at a real fetched source, and surface any sentence whose citation doesn’t hold up.
The audit step is where the ledger pays for itself. Atlas checks the finished draft against what it meant to answer, then catches dropped facts, unanswered slots, and citations that point nowhere. Because grounding happens last, the result includes result.unsupportedSentences: the sentences whose citations did not survive.
How it scores on DRACO
DRACO is Perplexity's open deep research benchmark: 100 real-world tasks across 10 domains, each graded against ~39 weighted criteria where wrong answers count against you. We ran a simple setup of Atlas on it next to the commercial agents.
The band is tight. Atlas on GPT-5.5 lands level with Perplexity Sonar, a hair above on Perplexity's own benchmark, and at lower cost. Atlas on Opus 4.8 sits next to Exa. Nobody runs away with it.
That is the point: an open harness you can fork and aim at your own sources scores in the same range as the closed products, not a tier below them.
Watch one run
Here’s a real run: Claude Opus 4.8 at balanced effort, reading a single SEC filing. The question asks Atlas to analyze a margin shift and adjust it for a one-time relocation loss:
Analyze how Rubber Leaf’s strategic shift from direct to indirect supply models has affected underlying profitability by examining gross margin performance across Q1 2023 and Q1 2024 […] then determine what Rubber Leaf’s Q1 2024 gross margin would be when excluding the factory relocation loss from total cost of sales.
Atlas turned that into a 15-slot ledger. A sample:
ask | shape | importance |
|---|---|---|
Year-over-year change in gross margin from Q1 2023 to Q1 2024 (in percentage points) |
| central |
Rubber Leaf’s adjusted Q1 2024 gross margin excluding the factory relocation loss |
| central |
How the indirect supply model alters cost structure and margin economics versus the direct model |
| central |
Verdict on whether margin pressure is driven by fundamental challenges in the indirect model or by temporary relocation costs |
| central |
Other one-time or non-recurring items affecting Q1 2024 cost of sales beyond the relocation loss |
| peripheral |
The asks avoid guessing the values. They name what Atlas has to establish. Each one closes as grounded with a value, quote, and source, or computed with run_code or synthesis across sources.
The report starts with the computed result: gross margin fell from +2.86% to -6.65%, a 9.52-point drop. Stripping out the $190,703 one-time relocation loss lifts it only to -0.20%. The more interesting part is what the run caught on the way:
the 10-Q’s MD&A “Gross profit margin” table states Total margins of 7% (2024) and 3% (2023) […] Those stated percentages do not reconcile with the negative gross profit reported on the company’s own income statement and appear to be a misstatement; the analysis below uses the gross profit and revenue figures from the consolidated statement of operations.
Atlas caught the contradiction in the filing and recomputed from the primary statements.
The whole run took about four minutes, and zero sentences failed citation grounding:
phase | time |
|---|---|
seed (ledger) | 9.8s |
gather | 89s |
synthesize | 44s |
coverage audit | 5.8s |
patch | 24s |
reconcile | 16s |
Three pages fetched, one cited, the filing itself.
Orchestrate researchers
By default, a run follows one spine. When a question needs more than one angle, you can register multiple researchers. Atlas decomposes the question, routes each sub-task to the best-fit worker (query → report), runs them in isolation, then synthesizes one cited report.
Any query → report worker plugs in: Exa deep research, Perplexity Sonar, parallel.ai, or your own. atlas.asResearcher(describe) exposes an Atlas instance as a worker, so fan-out can recurse. Omit researchers and Atlas stays on the single-spine path.
Uses Steel for browser fetches
Atlas can use Steel for browser fetches, so the loop reaches pages a basic fetch misses: JavaScript-rendered sites, sessions that need login state, pages that need a real browser to stay alive long enough to be useful.
Atlas can start with direct extraction and fall back to a Steel browser scrape when the page needs it. Search can come from Exa, Tavily, Brave, or the model provider’s own web search, so a run can use more than one source path.
The parts builders ask about
A single model runs everything. If you want more control, override research and write; unset roles fall back to the lead model.
Every model goes through the same wrapper: budget accounting, retries, caching, tracing, and the provider quirks that would otherwise leak into your code.
It keeps a trail. Atlas records searches and dead-end fetches so a later step can pick a new angle after a query goes nowhere. The trail is a plain record of what already wasted time.
It streams. Start a run and subscribe to events: report.delta carries the draft as it’s written, report.reset precedes each rewrite, source.fetched fires as pages come in. Await the final result when you want it.
It resumes. Journaled runs replay completed model, search, and fetch calls at no cost after a crash or deploy.
It returns structured output. Pass a schema and Atlas runs a final extraction pass over the finished report. You get a typed object alongside the markdown, on the single-spine path or the orchestrated path.
Safety
Atlas treats untrusted web content as data. Fetches pass SSRF guards. run_code runs in a memory-capped V8 isolate with no network, filesystem, or host access. Direct fetch honors robots.txt. Treat the SSRF guard as defense-in-depth; for hostile targets, run behind network-level egress controls. The README has the full picture.
Built with agents
Most of Atlas was written through AI pair-programming. The structural decisions are human: the shape of the loop, where the audit sits, what the ledger holds. The code came fast. The hard part was choosing what lives outside the model: the ledger, the budget meter, the trail of searches, the point where the run stops and checks its own work.
Built for verticals
Generic research tools hit a ceiling fast. Atlas is meant to be extended into a domain: a finance researcher that reads filings, a health researcher that works through clinical literature, a workflow with its own weird sources and review rules.
researchTool is for that. If the right source is EDGAR, PubMed, arXiv, OpenAlex, ClinicalTrials.gov, or your internal docs, wire it in directly; anything you add through ctx.addSource flows into the same source store, the same report, and the same grounding pass.
For a full example, the Atlas public company research demo shows the pattern applied to public biotech research with SEC filings, trial registries, PubMed, and optional Steel browser fetches.
Where Atlas needs care
Atlas grounds and audits. Weak sources still produce weak evidence; paywalled, missing, or contradictory sources still need a human’s judgment. The better you know your domain’s sources and failure modes, the better you can tune Atlas around them.
It also costs real money. A balanced run targets a couple of dollars, so runs need explicit budgets and caps. maxUSD is a best-effort target; provider calls can still land above it. If you bring a custom model, pass its pricing so the budget math stays honest.
Before you spend real money tuning a vertical, use the Browser Agent Leaderboards to narrow the model list. DRACO is the closest fit for Atlas because it grades full research reports across 100 expert-scored tasks, not short answers. Treat it as a filter, not a verdict: each row mixes a model, harness, judge, budget, and tool setup.
Get started
Install:
npm install @steel-dev/atlasPackage: @steel-dev/atlas on npm
Public company research demo: a biotech-company memo workflow using SEC EDGAR, ClinicalTrials.gov, PubMed, optional web search, and optional Steel browser fetches.
Questions? Discord or @steeldotdev.
This post is Day 4 of Steel Launch Week v3. See the full week at steel.dev/launch-week.
Launch Week v3 -> Day 04 / 05
Atlas is an open-source deep research harness you can run, fork, and bend around your own domain. It gives you the loop in one SDK: ask a question, gather evidence across the open web, and get back a cited report. Before it lands, Atlas checks the draft against the ledger and grounds the citations.
The job is simple: stop every team from rebuilding the same brittle research loop, while leaving the knobs exposed. Swap models, search providers, browser fetches, and domain sources.
This is the next step in Launch Week v3: Stealth Browser for the browser runtime, Dedicated IPs for stable network identity, Rust and Go SDKs for the services doing the work, and Atlas for the research layer.
Install it:
npmThen bring your model provider, wire in search or browser fetches, and start shaping the loop around your domain.
Why deep research is hard to build
A lot of teams are putting deep research agents inside their products. Some already use Steel for the browser side. The painful part is everything around it: planning the search, keeping sources straight, tracking what’s still unanswered, and staying inside a budget.
The common failure is quieter than a fake source. A long run reads a pile of pages, the early evidence gets summarized away, the writer drops a real fact it found twenty turns ago, and the final report looks clean while quietly missing the thing you asked for. Atlas is built around that failure.
How Atlas works
A single run is a loop built around a ledger.
The ledger is a coverage contract. Atlas breaks the question into slots: the things the answer has to cover. A slot pairs a question with its eventual grounded finding. Atlas strips numeric literals out of slot phrasing, so the planner has to earn the answer from evidence. As evidence arrives, each slot becomes grounded, computed from other slots, or marked exhausted with a reason.
The run moves through the ledger like this:
Plan. Seed the ledger with slots from the question.
Gather. A research agent searches, fetches, and reads, closing slots as it lands grounded answers.
Synthesize. Write the full report from what’s been gathered.
Audit. Walk the draft back against the ledger and find the gaps: open slots, facts the writer gathered then dropped.
Patch and reconcile. Fetch what’s missing, fill the gaps, then a final pass using only sources already in the store.
Ground. Renumber every citation, validate that each
[n]points at a real fetched source, and surface any sentence whose citation doesn’t hold up.
The audit step is where the ledger pays for itself. Atlas checks the finished draft against what it meant to answer, then catches dropped facts, unanswered slots, and citations that point nowhere. Because grounding happens last, the result includes result.unsupportedSentences: the sentences whose citations did not survive.
How it scores on DRACO
DRACO is Perplexity's open deep research benchmark: 100 real-world tasks across 10 domains, each graded against ~39 weighted criteria where wrong answers count against you. We ran a simple setup of Atlas on it next to the commercial agents.
The band is tight. Atlas on GPT-5.5 lands level with Perplexity Sonar, a hair above on Perplexity's own benchmark, and at lower cost. Atlas on Opus 4.8 sits next to Exa. Nobody runs away with it.
That is the point: an open harness you can fork and aim at your own sources scores in the same range as the closed products, not a tier below them.
Watch one run
Here’s a real run: Claude Opus 4.8 at balanced effort, reading a single SEC filing. The question asks Atlas to analyze a margin shift and adjust it for a one-time relocation loss:
Analyze how Rubber Leaf’s strategic shift from direct to indirect supply models has affected underlying profitability by examining gross margin performance across Q1 2023 and Q1 2024 […] then determine what Rubber Leaf’s Q1 2024 gross margin would be when excluding the factory relocation loss from total cost of sales.
Atlas turned that into a 15-slot ledger. A sample:
ask | shape | importance |
|---|---|---|
Year-over-year change in gross margin from Q1 2023 to Q1 2024 (in percentage points) |
| central |
Rubber Leaf’s adjusted Q1 2024 gross margin excluding the factory relocation loss |
| central |
How the indirect supply model alters cost structure and margin economics versus the direct model |
| central |
Verdict on whether margin pressure is driven by fundamental challenges in the indirect model or by temporary relocation costs |
| central |
Other one-time or non-recurring items affecting Q1 2024 cost of sales beyond the relocation loss |
| peripheral |
The asks avoid guessing the values. They name what Atlas has to establish. Each one closes as grounded with a value, quote, and source, or computed with run_code or synthesis across sources.
The report starts with the computed result: gross margin fell from +2.86% to -6.65%, a 9.52-point drop. Stripping out the $190,703 one-time relocation loss lifts it only to -0.20%. The more interesting part is what the run caught on the way:
the 10-Q’s MD&A “Gross profit margin” table states Total margins of 7% (2024) and 3% (2023) […] Those stated percentages do not reconcile with the negative gross profit reported on the company’s own income statement and appear to be a misstatement; the analysis below uses the gross profit and revenue figures from the consolidated statement of operations.
Atlas caught the contradiction in the filing and recomputed from the primary statements.
The whole run took about four minutes, and zero sentences failed citation grounding:
phase | time |
|---|---|
seed (ledger) | 9.8s |
gather | 89s |
synthesize | 44s |
coverage audit | 5.8s |
patch | 24s |
reconcile | 16s |
Three pages fetched, one cited, the filing itself.
Orchestrate researchers
By default, a run follows one spine. When a question needs more than one angle, you can register multiple researchers. Atlas decomposes the question, routes each sub-task to the best-fit worker (query → report), runs them in isolation, then synthesizes one cited report.
Any query → report worker plugs in: Exa deep research, Perplexity Sonar, parallel.ai, or your own. atlas.asResearcher(describe) exposes an Atlas instance as a worker, so fan-out can recurse. Omit researchers and Atlas stays on the single-spine path.
Uses Steel for browser fetches
Atlas can use Steel for browser fetches, so the loop reaches pages a basic fetch misses: JavaScript-rendered sites, sessions that need login state, pages that need a real browser to stay alive long enough to be useful.
Atlas can start with direct extraction and fall back to a Steel browser scrape when the page needs it. Search can come from Exa, Tavily, Brave, or the model provider’s own web search, so a run can use more than one source path.
The parts builders ask about
A single model runs everything. If you want more control, override research and write; unset roles fall back to the lead model.
Every model goes through the same wrapper: budget accounting, retries, caching, tracing, and the provider quirks that would otherwise leak into your code.
It keeps a trail. Atlas records searches and dead-end fetches so a later step can pick a new angle after a query goes nowhere. The trail is a plain record of what already wasted time.
It streams. Start a run and subscribe to events: report.delta carries the draft as it’s written, report.reset precedes each rewrite, source.fetched fires as pages come in. Await the final result when you want it.
It resumes. Journaled runs replay completed model, search, and fetch calls at no cost after a crash or deploy.
It returns structured output. Pass a schema and Atlas runs a final extraction pass over the finished report. You get a typed object alongside the markdown, on the single-spine path or the orchestrated path.
Safety
Atlas treats untrusted web content as data. Fetches pass SSRF guards. run_code runs in a memory-capped V8 isolate with no network, filesystem, or host access. Direct fetch honors robots.txt. Treat the SSRF guard as defense-in-depth; for hostile targets, run behind network-level egress controls. The README has the full picture.
Built with agents
Most of Atlas was written through AI pair-programming. The structural decisions are human: the shape of the loop, where the audit sits, what the ledger holds. The code came fast. The hard part was choosing what lives outside the model: the ledger, the budget meter, the trail of searches, the point where the run stops and checks its own work.
Built for verticals
Generic research tools hit a ceiling fast. Atlas is meant to be extended into a domain: a finance researcher that reads filings, a health researcher that works through clinical literature, a workflow with its own weird sources and review rules.
researchTool is for that. If the right source is EDGAR, PubMed, arXiv, OpenAlex, ClinicalTrials.gov, or your internal docs, wire it in directly; anything you add through ctx.addSource flows into the same source store, the same report, and the same grounding pass.
For a full example, the Atlas public company research demo shows the pattern applied to public biotech research with SEC filings, trial registries, PubMed, and optional Steel browser fetches.
Where Atlas needs care
Atlas grounds and audits. Weak sources still produce weak evidence; paywalled, missing, or contradictory sources still need a human’s judgment. The better you know your domain’s sources and failure modes, the better you can tune Atlas around them.
It also costs real money. A balanced run targets a couple of dollars, so runs need explicit budgets and caps. maxUSD is a best-effort target; provider calls can still land above it. If you bring a custom model, pass its pricing so the budget math stays honest.
Before you spend real money tuning a vertical, use the Browser Agent Leaderboards to narrow the model list. DRACO is the closest fit for Atlas because it grades full research reports across 100 expert-scored tasks, not short answers. Treat it as a filter, not a verdict: each row mixes a model, harness, judge, budget, and tool setup.
Get started
Install:
npm install @steel-dev/atlasPackage: @steel-dev/atlas on npm
Public company research demo: a biotech-company memo workflow using SEC EDGAR, ClinicalTrials.gov, PubMed, optional web search, and optional Steel browser fetches.
Questions? Discord or @steeldotdev.
This post is Day 4 of Steel Launch Week v3. See the full week at steel.dev/launch-week.


All Systems Operational