

TL;DR: Error messages are not just cleanup copy. For agent-facing products, they are one of the few places where the product gets to correct the agent while it is actively screwing up, before the user decides the whole thing is broken.
We've been overhauling errors recently. Not as a polish pass. Not because someone found religion about microcopy. Because the logs kept showing us the same ugly thing: people were failing, agents were confidently making it worse, and our product was giving them almost nothing useful at the moment it mattered.
When an error fails to do its job, the user (or the agent acting on their behalf) walks away assuming something is broken on our end. Usually it isn't. They just couldn't tell.
The principle I keep coming back to is simple.
Every bad error message is a missed activation. Every one. The error is the first place your product talks back to someone who is, right then, deciding whether you're worth their next hour. If it sounds confused, you sound confused. If it points them at the fix, you just bought yourself a little bit of trust.
I want to walk through what we're working on right now. Including one fight I had with a coding agent that I'm reversing my position on, live, in this article.
What we're moving every error toward
The shape we're trying to push every error into is roughly this: what happened, in the language of the user's input; which assumption or input was wrong; and how to do it correctly. Plus a link, ideally to a docs page that's structured to be parsed by an LLM as well as read by a human. Clean markdown.
We've built the mechanism to include docs links directly in JSON error responses, so when the user (or their agent) logs the failure, the link sits next to the message. Why this matters: a lot of what we were seeing came from people and agents who hadn't read the docs, or there was a page in the docs that already explained exactly what they'd hit, and they had no way to find it from inside their context.
Agents amplify that problem. They will confidently act on a bad prior unless the product corrects them at the moment of failure. That's the loop we're trying to close: the failure should carry the next useful pointer, instead of forcing the user or the agent to go hunting for it somewhere else.
Honestly though, the bigger lever has been embarrassingly simple: write the error like the person or agent reading it has never seen your docs, because they usually haven’t. Not more words. More context. A single sentence that names the cause and the fix beats a docs link the agent has to click to get to the same information.
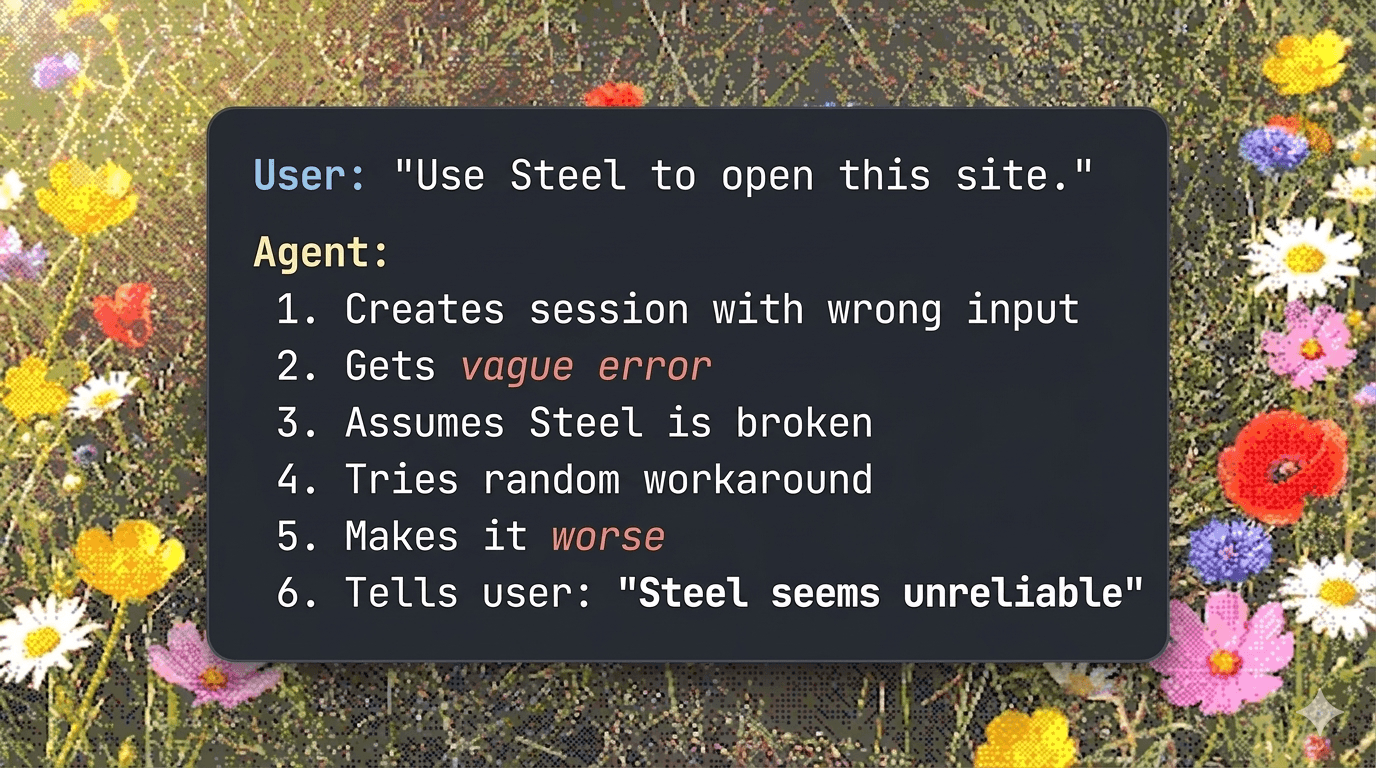
The UUID example
The cleanest before/after I have is the session ID error.
You can optionally pass your own session ID when you create a session in Steel, and it has to be a UUID. Users (and increasingly, coding agents) kept passing in random strings. Our original error was something like "format incorrect." It didn't really mean anything. The agent would see it, shrug, try a different random string. Technically accurate. Functionally useless. The worst category.
We changed it to tell the user, in one line, to pass a valid UUID. That was it. The error rate on that endpoint dropped by more than half. And this was before agents got good. Even regular users were hitting that one bad sentence and bouncing.
A vague error doesn't fail safely. It fails quietly into the category I'd describe as "the user concludes the product doesn't work." A specific error turns that same moment into a one-second correction.
The happy path gets users interested. The failure path decides whether they come back.
The Bearer fight
Steel doesn't use the Authorization header at all. Our auth header is a custom one: steel-api-key: <your-key>. The reason was boring and practical: Steel spends a lot of time around other people’s websites, cookies, proxies, sessions, and auth state, so we wanted our control-plane auth to be extremely explicit. steel-api-key is ugly in a useful way: you can see exactly what it is.
People kept sending us Authorization: Bearer <your-key> anyway. Mostly coding agents. The agents were confused in the most boring possible way: they had seen ten million APIs use Bearer auth, and decided ours did too. The model would confidently tell users that's how the API works, they'd paste the snippet, the request would fail. We'd see the same pattern over and over in the logs.
First push: a clear error that said we don't use Bearer, with a link to the docs. The error fired. It barely moved the needle. My best guess is that the model already had Bearer baked in deep, from an old crawl or just generic API priors, and one error wasn't going to dent it.
At that point, the practical answer looked obvious: accept what agents were already sending.
So we caved. We started accepting Authorization: Bearer <your-key> as a silent alias alongside the canonical header. The bet was we could remove the alias later, once the data showed people were converging on the right one. This is the kind of sentence engineers write shortly before creating permanent compatibility debt.
Note: I am now increasingly convinced this was wrong, which is annoying because I was there when we did it. Talking it through with the team changed how I think about what an error actually is.
The last surface that doesn't get distilled
Almost everything else we ship gets quietly absorbed by the model companies on the other end.
Docs go into training dataset, then through retrieval, then through whatever summarization the agent runs before it acts. SDK examples get rewritten in whatever the model already prefers. Blog posts get compressed into one-liners long before they reach a decision.

By the time any of that lands in the loop where the agent is choosing how to call Steel, it's been through several layers of compression.
Errors are different. The error fires inside the agent's loop in real time, because the request just failed and the agent has to decide what to do next. Nothing sits in between. No retrieval pass, no distillation, no helpful little summary. The model is reading what we actually wrote, at the moment it has to act on it.
That's a different writing surface from anything else we ship. Docs depend on training cycles. SDK examples get filtered through whatever the model already thinks your API looks like. Errors don't. They're the last place where you can still teach the model something specific about your product, and have a reasonable expectation that the message lands intact.
Which is exactly why accepting Bearer may have been the wrong call. We traded away the one surface where the product could correct the agent, in exchange for short-term ergonomics. We took ourselves out of the loop.
Hard errors, soft errors, and the FYI channel
Once you start thinking this way, you notice that a lot of what an agent needs from you isn't even an error.
CLIs have had this pattern forever. Warning, you're probably doing this wrong, FYI, I'll still let you run it. That same shape belongs in agent-facing surfaces, and we're not doing nearly enough of it.
The agent creates a session, the request succeeds, and somewhere in the next two minutes the session is going to break because they're on a site that needs a proxy. A passive "FYI, you probably want a proxy here" is worth more than the hard error five minutes later, when the session is already trashed.
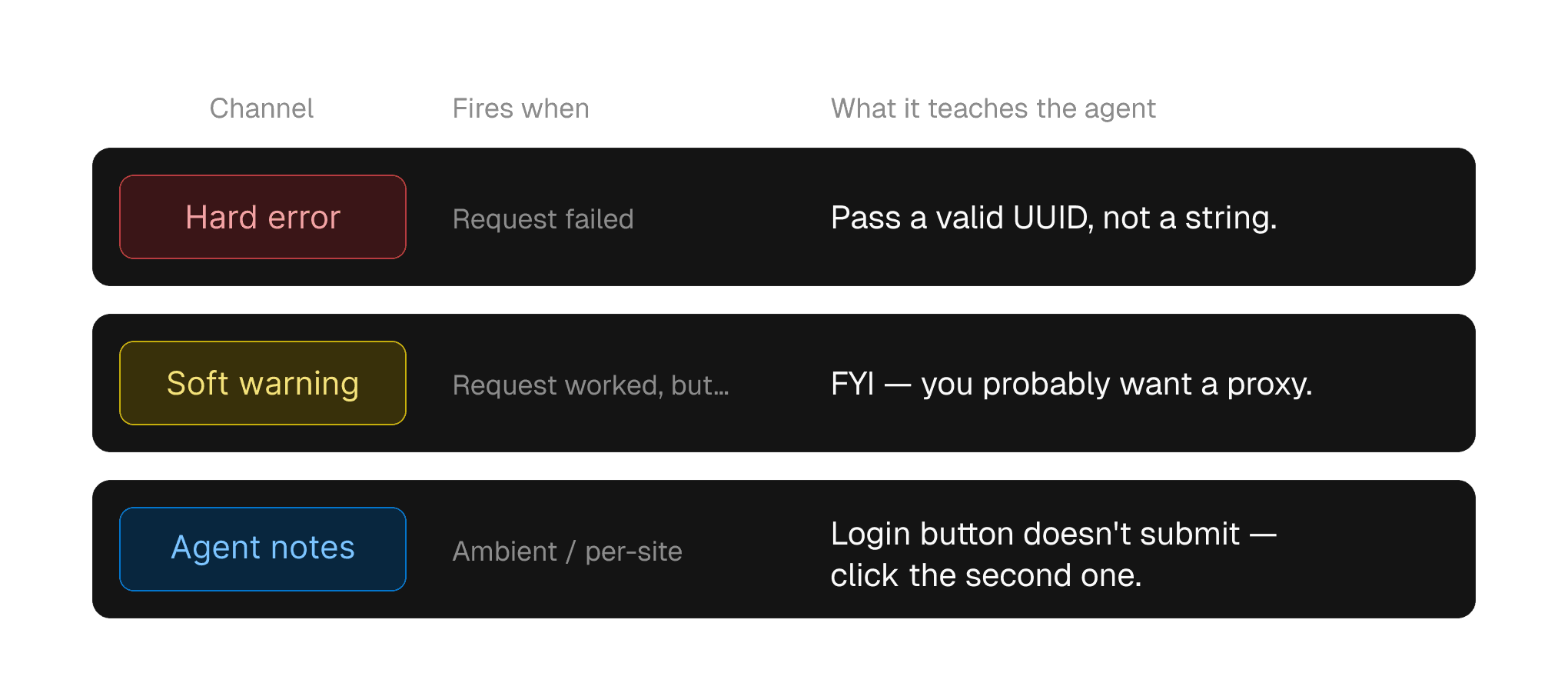
So the model in my head is roughly three channels. The hard error: the request failed, here's the cause and the fix, return them inline. The soft warning: the request worked, but you're heading somewhere you'll regret. And passive context: things that are just true about the environment the agent is operating in (this site, this session, this auth state) that the agent should know without having to ask.
The third one is where I think the most interesting work is.
Agent notes, and generating errors from the data
There's a version of that third channel we've been kicking around. Internally we call them agent notes. Small, scoped pieces of context, attached at whatever level of granularity makes sense. Some are general; about sessions, about antibot. Some are per-site or per-URL. "On this page, the visible login button doesn't actually submit, click the second one." That kind of thing.
You don't have to hand-write all of them. We already capture session tags and events for the common situations users and agents end up in. Cluster those, find the recurring failure shapes, and you've got the raw material to either write better errors or generate per-context notes against the actual distribution of what's going wrong. Past a certain volume, the loop automates itself. Detect the cluster, draft the note, ship the fix.
A lot of what we've historically tried to handle with skills (pre-written instructions for an agent about how to use Steel) collapses if the tool teaches well enough in the moment. The skill is doing extra work because the error isn't.
Progressive disclosure, and the CLI logs thing
The other thing we are working on, partly in service of all of this, is real-time CLI logs the agent can follow, grep, tail, head. Basically consume the way a human consumes a long log file. Open one log at a time. Scan. Decide whether you need more.
It's the same shape Anthropic uses in Claude Code. A small model decides whether the doc is needed at all, then which section, then the full file if it has to. Progressive disclosure. I think that's exactly how agent-facing logs should work. The agent doesn't want everything. It wants the next useful thing, and the ability to ask for more if that's not enough.
The reason this matters for errors: the error is the entry point into that log. If the error is good, the agent might not need the log at all. If the error is bad, the log is where the agent has to go to recover. Right now, for most infra products, that path doesn't really exist.
Why "activation" is the right word
I want to come back to why I think activation is the right frame, and not, say, developer experience, agent experience, or error UX.
When a user (or an agent) hits a confused error, the default assumption isn't "I made a mistake." It's "this product is broken."
Or, almost as bad: "this is too hard to figure out, not for me." Either way, you've lost the activation. You don't get a second chance to teach them. They leave, and honestly they're right to leave, because from where they're sitting you didn't give them any reason to stay.
A good error does the opposite. The product told them, in one line, what they got wrong and how to fix it. That sounds small, but it changes what the user assumes about the system.
What I think we're really doing
The biggest unlock for anything agentic is the feedback loop (we already do a version of this with Agent Traces). Close it, and the agent figures everything out on its own. Leave it open, and nothing on the prompt side rescues you.
Errors are the densest part of that loop. They're the moment the system tells the agent something it didn't already know. There's a version of the future where this gets its own channel. An agent mailbox, parallel to the API response, where we can push context and warnings that a human user doesn't need but an agent does.
We're not there yet. But it points at the same thing the rest of this points at. The failure path of your product is a teaching surface. And right now it's the only surface the agent actually has to read.
Try this in your own product: take the 10 most common API errors, rewrite each one as a recovery instruction, and measure whether retries improve.


All Systems Operational